GPT¶
- Inspired by Andrej Karpathy's "Let's build GPT: from scratch, in code, spelled out."
- Supplementary links
- Attention is All You Need paper from Google
- OpenAI GPT-3 Paper
- OpenAI ChatGPT blog post
- nanoGPT
- Lambda GPU Cloud via lambda labs provides GPU access for model training. The best and easiest way to spin up an on-demand GPU instance in the cloud is if you can ssh to: https://lambdalabs.com . If you prefer to work in notebooks, I think the easiest path today is Google Colab.
Table of Contents¶
- 0. Introduction
- 1. Baseline Bigram Language Model (LM)
- 2. Self-Attention
- 2.1. V1: Averaging Past Context with
ForLoops - Weakest Form of Aggregation - 2.2. Trick: Matrix Multiplication as Weighted Aggregation
- 2.3. V2: Matrix Multiplication
- 2.4. V3: Softmax
- 2.5. Bigram LM Code Tweaks: Robust Token Embedding Dimension
- 2.6. Bigram LM Code Tweaks: Positional Encoding
- 2.7. V4: SELF-ATTENTION
- 2.8. 6 Key Notes on Attention
- 2.1. V1: Averaging Past Context with
- 3. Transformers
- 3.1. Single Self-Attention
- 3.2. Multi-Head Attention (MHA)
- 3.3. Feed-Forward Network (FFN)
- 3.4. Residual Connections
- 3.5. Layer Normalization (
LayerNorm) - 3.6. Scaling Up the Model
- 3.7. Putting It All Together
- 3.8. Encoder vs Decoder vs Encoder-Decoder Transformers
- 3.9. Quick Walkthrough of
nanoGPT - 3.10. ChatGPT, GPT-3: pretraining vs. finetuning, RLHF
- 4. Conclusion
Appendix¶
Figures¶
- A1. Query, Key, Value in Self-Attention Explained.
- A2. Scaled Dot-Product Attention.
- A3. Attention is All You Need - Transformer Model Architecture.
- A4. Multi-Head Attention.
- A5. Feed-Forward Network.
- A6. Residual Block: (1)-Residual Connection on the Side of the Layer, (2)-Layer on the Side of the Residual Connection.
- A7. Layer Normalization.
- A8. Dropout.
- A9. Decoder Transformer (GPT) Model Architecture.
Equations¶
- B1. Scaled Dot-Product Attention
- B2. Multi-Head Attention
- B3. Feed-Forward Network
- B4. Residual Connections
- B5. Layer Normalization
Definitions/Explanations¶
- C1. Attention
- C2. Masking
- C3. Translation Invariance
- C4. Self-Attention
- C5. Self-Attention vs Cross Attention
- C6. Residual Connections
- C7. Layer Normalization
- C8. Dropout
- C9. Saving & Loading Model & Model Weights
Suggested Exercises¶
References¶
0. Introduction¶
We build a GPT, following the paper "Attention is All You Need" and OpenAI's GPT-2 / GPT-3. We talk about connections to ChatGPT, which has taken the world by storm. We watch GitHub Copilot, itself a GPT, help us write a GPT (meta :D!). We'll utilise the small "Tiny Shakespeare" dataset, which contains all of Shakespeare's work in a single file under $1$ MB, instead of a bigger chunk-sized entire internet dataset. This will tremendously reduce our parameter size from the billions. For simplicity and speed, our input tokens will be characters and not words. It's essential to watch the earlier makemore videos to get comfortable with the autoregressive language modeling framework, and basics of tensors & PyTorch's torch.nn, which we take for granted in this video.
ChatGPT is a language model (LM) developed & designed by OpenAI to understand and generate human-like text sequentially based on the input it receives. You can use it for various natural language processing tasks, such as answering questions, having conversations, generating text, and more. For the same input, it provides different outputs when it's rerun numerous times. This shows that it's a probabilistic LM.
Generative Pre-trained Transformer, otherwise known as GPT, is a LM that is trained on a siginificant large size of text data to understand and generate human-like text sequentially. The "transformer" part refers to the model's architecture, which was introduced and inspired by the 2017 "Attention Is All You Need" paper.
Current implementations from micrograd (n-grams LM) to makemore (MLP, CNN, RNN) and now GPT follow a few key papers:
- Bigram (one character predicts the next one with a lookup table of counts)
- MLP, following Bengio et al. 2003
- CNN, following DeepMind WaveNet 2016 (in progress...)
- RNN, following Mikolov et al. 2010
- LSTM, following Graves et al. 2014
- GRU, following Kyunghyun Cho et al. 2014
- Transformer, following Vaswani et al. 2017
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import torch
import torch.nn as nn
from torch.nn import functional as F
import matplotlib.pyplot as plt
import math
import numpy as np
1. Baseline Bigram Language Model (LM)¶
We establish a simple bigram language model (LM) to get started as our baseline LM. We build our dataset, create our input tokens, split it into train and validation sets, create our bigram LM, train the model and then measure the model performance via cross-entropy loss.
1.1. Data Reading & Exploration¶
Let's download the Tiny Shakespeare dataset, which is about a $1$ MB file, that contains all of Shakespeare's work in one single text file. We read in the text file and, upon inspection, discover it has ~$1$ million characters.
!wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
with open('input.txt', 'r', encoding='utf-8') as f:
text = f.read()
--2024-06-12 15:53:19-- https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.110.133, 185.199.111.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 1115394 (1.1M) [text/plain] Saving to: 'input.txt' input.txt 100%[===================>] 1.06M --.-KB/s in 0.02s 2024-06-12 15:53:20 (46.2 MB/s) - 'input.txt' saved [1115394/1115394]
Vocabulary¶
Since we are using character instead of word/sub-word tokens, our vocabulary will just be the different unique characters that appear in our dataset. Notice that the $1$st character is the newline character, \n, and the $2$nd is the space character, " ".
print("length of dataset in characters: ", len(text), '\n')
# here are all the unique characters that occur in this text
chars = sorted(list(set(text)))
vocab_size = len(chars)
print("Unique characters in dataset",''.join(chars))
print("\nTotal number of unique characters in dataset:", vocab_size, '\n')
# let's look at the first 1000 characters
print('----------------------------------------------------------------')
print(text[:1000])
length of dataset in characters: 1115394 Unique characters in dataset !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz Total number of unique characters in dataset: 65 ---------------------------------------------------------------- First Citizen: Before we proceed any further, hear me speak. All: Speak, speak. First Citizen: You are all resolved rather to die than to famish? All: Resolved. resolved. First Citizen: First, you know Caius Marcius is chief enemy to the people. All: We know't, we know't. First Citizen: Let us kill him, and we'll have corn at our own price. Is't a verdict? All: No more talking on't; let it be done: away, away! Second Citizen: One word, good citizens. First Citizen: We are accounted poor citizens, the patricians good. What authority surfeits on would relieve us: if they would yield us but the superfluity, while it were wholesome, we might guess they relieved us humanely; but they think we are too dear: the leanness that afflicts us, the object of our misery, is as an inventory to particularise their abundance; our sufferance is a gain to them Let us revenge this with our pikes, ere we become rakes: for the gods know I speak this in hunger for bread, not in thirst for revenge.
1.2. Tokenization & Train-Dev Split¶
A tokenizer is a component used in natural language processing (NLP) to convert raw text of strings into some sequence of integers known as "tokens". An encoder allows us turn tokens represented as strings into integers, and a decoder allows us to turn our tokens represented as integers back into strings.
We have a very simple character-level tokenizer. There are many different tokenizers, like Google's SentencePiece schema (a subword tokenizer) or OpenAI's tiktoken (a byte pair encoding, BPE, tokenizer). These tokenizers operate fundamentally on a sub-word level, which means their vocabulary is much larger (since there are many more permutations of subwords than characters). But the general idea remains the same, we are just turning strings into integers and vice versa.
The large vocabulary size of tiktoken, which is $50257$, enables us to encode a string to a shorter sequence of integers as compared to our own tokenizer of size 65 which generates a longer sequence of integer tokens. The larger the vocabulary size, the shorter the sequence of integer tokens.
So, once we define our encoder and decoder we can then encode our entire dataset. Once we have our encoded dataset, we perform a $90\%:10\%$ train-validation split.
# create a mapping from characters to integers (codebook for characters)
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
# encoder-decoder functions
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
print(encode("hii there"))
print(decode(encode("hii there")))
[46, 47, 47, 1, 58, 46, 43, 56, 43] hii there
# let's now encode the entire text dataset and store it into a torch.Tensor
import torch
data = torch.tensor(encode(text), dtype=torch.long)
print(data.shape, data.dtype)
print(data[:1000]) # the 1000 characters we looked at earier will to the GPT look like this
torch.Size([1115394]) torch.int64
tensor([18, 47, 56, 57, 58, 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 14, 43, 44,
53, 56, 43, 1, 61, 43, 1, 54, 56, 53, 41, 43, 43, 42, 1, 39, 52, 63,
1, 44, 59, 56, 58, 46, 43, 56, 6, 1, 46, 43, 39, 56, 1, 51, 43, 1,
57, 54, 43, 39, 49, 8, 0, 0, 13, 50, 50, 10, 0, 31, 54, 43, 39, 49,
6, 1, 57, 54, 43, 39, 49, 8, 0, 0, 18, 47, 56, 57, 58, 1, 15, 47,
58, 47, 64, 43, 52, 10, 0, 37, 53, 59, 1, 39, 56, 43, 1, 39, 50, 50,
1, 56, 43, 57, 53, 50, 60, 43, 42, 1, 56, 39, 58, 46, 43, 56, 1, 58,
53, 1, 42, 47, 43, 1, 58, 46, 39, 52, 1, 58, 53, 1, 44, 39, 51, 47,
57, 46, 12, 0, 0, 13, 50, 50, 10, 0, 30, 43, 57, 53, 50, 60, 43, 42,
8, 1, 56, 43, 57, 53, 50, 60, 43, 42, 8, 0, 0, 18, 47, 56, 57, 58,
1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 18, 47, 56, 57, 58, 6, 1, 63,
53, 59, 1, 49, 52, 53, 61, 1, 15, 39, 47, 59, 57, 1, 25, 39, 56, 41,
47, 59, 57, 1, 47, 57, 1, 41, 46, 47, 43, 44, 1, 43, 52, 43, 51, 63,
1, 58, 53, 1, 58, 46, 43, 1, 54, 43, 53, 54, 50, 43, 8, 0, 0, 13,
50, 50, 10, 0, 35, 43, 1, 49, 52, 53, 61, 5, 58, 6, 1, 61, 43, 1,
49, 52, 53, 61, 5, 58, 8, 0, 0, 18, 47, 56, 57, 58, 1, 15, 47, 58,
47, 64, 43, 52, 10, 0, 24, 43, 58, 1, 59, 57, 1, 49, 47, 50, 50, 1,
46, 47, 51, 6, 1, 39, 52, 42, 1, 61, 43, 5, 50, 50, 1, 46, 39, 60,
43, 1, 41, 53, 56, 52, 1, 39, 58, 1, 53, 59, 56, 1, 53, 61, 52, 1,
54, 56, 47, 41, 43, 8, 0, 21, 57, 5, 58, 1, 39, 1, 60, 43, 56, 42,
47, 41, 58, 12, 0, 0, 13, 50, 50, 10, 0, 26, 53, 1, 51, 53, 56, 43,
1, 58, 39, 50, 49, 47, 52, 45, 1, 53, 52, 5, 58, 11, 1, 50, 43, 58,
1, 47, 58, 1, 40, 43, 1, 42, 53, 52, 43, 10, 1, 39, 61, 39, 63, 6,
1, 39, 61, 39, 63, 2, 0, 0, 31, 43, 41, 53, 52, 42, 1, 15, 47, 58,
47, 64, 43, 52, 10, 0, 27, 52, 43, 1, 61, 53, 56, 42, 6, 1, 45, 53,
53, 42, 1, 41, 47, 58, 47, 64, 43, 52, 57, 8, 0, 0, 18, 47, 56, 57,
58, 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 35, 43, 1, 39, 56, 43, 1,
39, 41, 41, 53, 59, 52, 58, 43, 42, 1, 54, 53, 53, 56, 1, 41, 47, 58,
47, 64, 43, 52, 57, 6, 1, 58, 46, 43, 1, 54, 39, 58, 56, 47, 41, 47,
39, 52, 57, 1, 45, 53, 53, 42, 8, 0, 35, 46, 39, 58, 1, 39, 59, 58,
46, 53, 56, 47, 58, 63, 1, 57, 59, 56, 44, 43, 47, 58, 57, 1, 53, 52,
1, 61, 53, 59, 50, 42, 1, 56, 43, 50, 47, 43, 60, 43, 1, 59, 57, 10,
1, 47, 44, 1, 58, 46, 43, 63, 0, 61, 53, 59, 50, 42, 1, 63, 47, 43,
50, 42, 1, 59, 57, 1, 40, 59, 58, 1, 58, 46, 43, 1, 57, 59, 54, 43,
56, 44, 50, 59, 47, 58, 63, 6, 1, 61, 46, 47, 50, 43, 1, 47, 58, 1,
61, 43, 56, 43, 0, 61, 46, 53, 50, 43, 57, 53, 51, 43, 6, 1, 61, 43,
1, 51, 47, 45, 46, 58, 1, 45, 59, 43, 57, 57, 1, 58, 46, 43, 63, 1,
56, 43, 50, 47, 43, 60, 43, 42, 1, 59, 57, 1, 46, 59, 51, 39, 52, 43,
50, 63, 11, 0, 40, 59, 58, 1, 58, 46, 43, 63, 1, 58, 46, 47, 52, 49,
1, 61, 43, 1, 39, 56, 43, 1, 58, 53, 53, 1, 42, 43, 39, 56, 10, 1,
58, 46, 43, 1, 50, 43, 39, 52, 52, 43, 57, 57, 1, 58, 46, 39, 58, 0,
39, 44, 44, 50, 47, 41, 58, 57, 1, 59, 57, 6, 1, 58, 46, 43, 1, 53,
40, 48, 43, 41, 58, 1, 53, 44, 1, 53, 59, 56, 1, 51, 47, 57, 43, 56,
63, 6, 1, 47, 57, 1, 39, 57, 1, 39, 52, 0, 47, 52, 60, 43, 52, 58,
53, 56, 63, 1, 58, 53, 1, 54, 39, 56, 58, 47, 41, 59, 50, 39, 56, 47,
57, 43, 1, 58, 46, 43, 47, 56, 1, 39, 40, 59, 52, 42, 39, 52, 41, 43,
11, 1, 53, 59, 56, 0, 57, 59, 44, 44, 43, 56, 39, 52, 41, 43, 1, 47,
57, 1, 39, 1, 45, 39, 47, 52, 1, 58, 53, 1, 58, 46, 43, 51, 1, 24,
43, 58, 1, 59, 57, 1, 56, 43, 60, 43, 52, 45, 43, 1, 58, 46, 47, 57,
1, 61, 47, 58, 46, 0, 53, 59, 56, 1, 54, 47, 49, 43, 57, 6, 1, 43,
56, 43, 1, 61, 43, 1, 40, 43, 41, 53, 51, 43, 1, 56, 39, 49, 43, 57,
10, 1, 44, 53, 56, 1, 58, 46, 43, 1, 45, 53, 42, 57, 1, 49, 52, 53,
61, 1, 21, 0, 57, 54, 43, 39, 49, 1, 58, 46, 47, 57, 1, 47, 52, 1,
46, 59, 52, 45, 43, 56, 1, 44, 53, 56, 1, 40, 56, 43, 39, 42, 6, 1,
52, 53, 58, 1, 47, 52, 1, 58, 46, 47, 56, 57, 58, 1, 44, 53, 56, 1,
56, 43, 60, 43, 52, 45, 43, 8, 0, 0])
# Let's now split up the data into train and validation sets
n = int(0.9*len(data)) # first 90% will be train, remaining 10% will be val
train_data = data[:n]
val_data = data[n:]
1.3. Data Loader: Batches¶
Let's prepare the model input. We will never feed our model the entire sequence of tokens as prompt at once. Instead, we will feed it a randomly drawn but consecutive sequence of tokens. The model will then predict the next token in the sequence from this prompt.
We refer to these consecutive, size-limited input sequences of tokens as blocks. Size-limited means that blocks can have a length of up to
block_size.
When we sample our dataset, we grab a block of $8$ characters of context plus 1 final character as target. The goal is to learn from the target character during training, predict from the target during evaluation, and generate text from the target during inference.
Suppose we have a block_size of $8$, each block actually contains 8 different examples, one for each possible sequence starting with the $1$st initial character. It is important to show our model examples with fewer than block_size characters, so that it can learn how to generate text with as little as one character context. Essentially, the transformer should be robust to varying context lengths (1 to block_size), which is essential during inference (adequate text generation during sampling with as little as context length of 1 to block_size).
block_size = 8 # context length
train_data[:block_size+1]
tensor([18, 47, 56, 57, 58, 1, 15, 47, 58])
x = train_data[:block_size]
y = train_data[1:block_size+1]
for t in range(block_size):
context = x[:t+1]
target = y[t]
print(f"when input is {context} the target: {target}")
when input is tensor([18]) the target: 47 when input is tensor([18, 47]) the target: 56 when input is tensor([18, 47, 56]) the target: 57 when input is tensor([18, 47, 56, 57]) the target: 58 when input is tensor([18, 47, 56, 57, 58]) the target: 1 when input is tensor([18, 47, 56, 57, 58, 1]) the target: 15 when input is tensor([18, 47, 56, 57, 58, 1, 15]) the target: 47 when input is tensor([18, 47, 56, 57, 58, 1, 15, 47]) the target: 58
print('X:', decode(x.tolist()), ' || y:', decode(y.tolist()),'\n')
for t in range(block_size):
context = x[:t+1].tolist()
target = y[t].tolist()
print(f"{decode(context)} → {decode([target])}")
X: First Ci || y: irst Cit F → i Fi → r Fir → s Firs → t First → First → C First C → i First Ci → t
In the cell above, the representation of X and y is different from our makemore version. In makemore, we had a fixed input context size, and we padded with . in cases where the names were not the full context length. Here, we append each subsequent character step-by-step to ensure the LM learns robustly to varying context lengths from 1 to block_size.
Now, we feed in the dataset in batches of multiple chunks of text that are all stacked up like in a single tensor. This is done for efficiency and speed since GPUs are good at parallel processing/computing. The batches are processed simultaneously and independently of each other.
Since we have batch_size 4 and block_size 8, one batch will contain a $4\times8$ tensor $X$ and a $4\times8$ tensor $Y$.
- Each row, as a single sample, contains 8 different example contexts, one for each possible sequence starting with the $1$st character until the
block_size. - There are 4 rows for the 4 samples in a single batch of
batch_size4. Each row has 8 examples, therefore there's a total of 32 training samples. - Each element in the 4x8 tensor Y contains a single target, each corresponding to one of the 32 examples in X.
torch.manual_seed(1337)
batch_size = 4 # how many independent sequences will we process in parallel?
block_size = 8 # what is the maximum context length for predictions?
def get_batch(split):
# generate a small batch (batch_size, block_size) of data of inputs x and targets y
data = train_data if split == 'train' else val_data
# randomly sample a bunch of block_size length sequences
ix = torch.randint(len(data) - block_size, (batch_size,)) # (batch_size, )
# the sequence (stack each sequence of the batch indices to form a tensor)
x = torch.stack([data[i:i+block_size] for i in ix]) # (batch_size, block_size)
# the target (next character)
y = torch.stack([data[i+1:i+block_size+1] for i in ix]) # (batch_size, block_size)
return x, y
xb, yb = get_batch('train')
print('inputs:')
print(xb.shape)
print(xb)
print('targets:')
print(yb.shape)
print(yb)
print('----')
for b in range(batch_size): # batch dimension: number of sequences in the batch (batch_size)
for t in range(block_size): # time dimension: number of tokens in the sequence (block_size)
context = xb[b, :t+1] # context: taking the first t+1 tokens from the b-th sequence in the input batch
target = yb[b,t] # target to predict: take the t-th token from the b-th sequence in the target batch
print(f"when input is {context.tolist()} the target: {target}")
inputs:
torch.Size([4, 8])
tensor([[24, 43, 58, 5, 57, 1, 46, 43],
[44, 53, 56, 1, 58, 46, 39, 58],
[52, 58, 1, 58, 46, 39, 58, 1],
[25, 17, 27, 10, 0, 21, 1, 54]])
targets:
torch.Size([4, 8])
tensor([[43, 58, 5, 57, 1, 46, 43, 39],
[53, 56, 1, 58, 46, 39, 58, 1],
[58, 1, 58, 46, 39, 58, 1, 46],
[17, 27, 10, 0, 21, 1, 54, 39]])
----
when input is [24] the target: 43
when input is [24, 43] the target: 58
when input is [24, 43, 58] the target: 5
when input is [24, 43, 58, 5] the target: 57
when input is [24, 43, 58, 5, 57] the target: 1
when input is [24, 43, 58, 5, 57, 1] the target: 46
when input is [24, 43, 58, 5, 57, 1, 46] the target: 43
when input is [24, 43, 58, 5, 57, 1, 46, 43] the target: 39
when input is [44] the target: 53
when input is [44, 53] the target: 56
when input is [44, 53, 56] the target: 1
when input is [44, 53, 56, 1] the target: 58
when input is [44, 53, 56, 1, 58] the target: 46
when input is [44, 53, 56, 1, 58, 46] the target: 39
when input is [44, 53, 56, 1, 58, 46, 39] the target: 58
when input is [44, 53, 56, 1, 58, 46, 39, 58] the target: 1
when input is [52] the target: 58
when input is [52, 58] the target: 1
when input is [52, 58, 1] the target: 58
when input is [52, 58, 1, 58] the target: 46
when input is [52, 58, 1, 58, 46] the target: 39
when input is [52, 58, 1, 58, 46, 39] the target: 58
when input is [52, 58, 1, 58, 46, 39, 58] the target: 1
when input is [52, 58, 1, 58, 46, 39, 58, 1] the target: 46
when input is [25] the target: 17
when input is [25, 17] the target: 27
when input is [25, 17, 27] the target: 10
when input is [25, 17, 27, 10] the target: 0
when input is [25, 17, 27, 10, 0] the target: 21
when input is [25, 17, 27, 10, 0, 21] the target: 1
when input is [25, 17, 27, 10, 0, 21, 1] the target: 54
when input is [25, 17, 27, 10, 0, 21, 1, 54] the target: 39
1.4. Bigram LM¶
Lets start with the simplest model possible, which is a bigram language model, a character-level language model that generates the next character based on the previous one and bases its generation on the probability of two characters occurring together.
Forward pass¶
Below we implement the bigram language model using an embedding with exactly vocab_size x vocab_size. Embedding a single integer between 0 and vocab_size-1 would return a tensor of length vocab_size. This acts like a lookup table, where passing in a row index between 0 and vocab_size-1 would return a row with length vocab_size. We simply initialize an embedding that maps each token to a probability distribution for the next token.
If we pass in a multi-demensional vector as input, the embedding simply returns a tensor with the same dimensions, excecpt each integer gets turned into a vector of vocab_size. For example, if we pass in an input with dimensions BxT, then the output will be have dimension BxTxC.
Bis the "batch" dimension, indicating which sequence of the batch we are in, equal tobatch_size.Tis the "time" dimension, indicating our position in the sequence, equal toblock_size.Cis the "channel" dimension, indicating which neuron we are talking about, equal tovocab_size.
Ensure you pass in logits and target with the right shape when calling F.cross_entropy. The loss we expect, given a uniform distribution, to make a prediction is:
$$-ln(\frac{1}{vocab\_size})=-ln(\frac{1}{65})=4.17387$$
However, we get a higher loss of $\boldsymbol{4.8786}$ which shows that initial predictions are not super diffused or evenly spread out across the entire vocab_size and contain a bit of entropy.
-np.log(1/vocab_size) # vocab_size = 65
4.174387269895637
torch.manual_seed(1337)
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)
def forward(self, idx, targets=None):
# idx and targets are both (B,T) tensor of integers
logits = self.token_embedding_table(idx) # (B,T,C) = (batch_size, time=block_size, channels=vocab_size)
if targets is None: # don't compute loss if targets not given (used for generation)
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C) # (B x T, C)
targets = targets.view(B*T) # (B x T)
loss = F.cross_entropy(logits, targets) # F.cross_entropy inputs shape (B, C, T)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# get the predictions
logits, loss = self(idx)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1) ... (B, T+max_new_tokens)
return idx
bigramLM = BigramLanguageModel(vocab_size)
logits, loss = bigramLM(xb, yb)
print(logits.shape)
print(loss)
torch.Size([32, 65]) tensor(4.8786, grad_fn=<NllLossBackward0>)
Generate¶
Let's add the ability to generate characters to our model. To generate our output, we take the logits which would be the conditional probabilities of two characters occurring together after the last function, and extract the last token in each block because that will be the token that we will use for generating the succeeding characters. Then, we apply softmax on the last dimension which contains the output probabilities.
generate takes some context and uses it to generate max_new_tokens more characters.
For each new token up to max_new_tokens:
- call the forward pass with the given context
idx(without targets) to get the logits - "pluck out" the logits for just the last position in dimension
T(since our forward pass acts on allBxTinputs and returnsBxTxC) - apply softmax to the last position (
BxC) to transform into probabilities
Softmax essentially amplifies the differences between the elements of the input vector, converting them into probabilities that represent the likelihood of each class or category. The softmax function transforms logits (raw scores) into probabilities that sum up to 1, and each probability represents the likelihood of a particular class. The distribution of these probabilities depends on the distribution of the logits themselves.
- sample from the probability distribution to generate the next character
- append generated character to context and "shift" the context window
- repeat
See that self(idx) calls the forward function of the model. forward is adapted accordingly above to also take a call with just idx.
# initial context is just a 0 (new line character) with shape 1x1 (1 character, 1 batch)
idx = torch.zeros((1, 1), dtype=torch.long)
# generate 100 new tokens
res = bigramLM.generate(idx, max_new_tokens=100)
# since generate returns a batch of sequences, we just take the first one
res0 = res[0]
# decode the sequence of indices into characters
print(decode(res0.tolist()))
# print(decode(bigramLM.generate(
# torch.zeros((1, 1), dtype=torch.long),
# max_new_tokens=100)[0].tolist()))
Sr?qP-QWktXoL&jLDJgOLVz'RIoDqHdhsV&vLLxatjscMpwLERSPyao.qfzs$Ys$zF-w,;eEkzxjgCKFChs!iWW.ObzDnxA Ms$3
1.5. Training Bigram LM¶
Let's train our model. Let's setup our optimization routine. We will use the AdamW optimizer.
SGD (Stochastic Gradient Descent): A fundamental optimization algorithm used in machine learning and deep learning. It updates model parameters by computing gradients using randomly selected small batches of data, making it "stochastic." It's widely used for training neural networks and other machine learning models.
Adam (Adaptive Moment Estimation): A popular optimization algorithm that improves convergence and training speed compared to traditional SGD. It maintains moving averages of gradients and adapts learning rates for each parameter. It's known for its efficiency in practice.
AdamW: A modification of the Adam optimizer designed to handle weight decay (L2 regularization) more effectively. It separates weight decay from the optimization process, making it better at controlling overfitting during the training of deep neural networks. It's a preferred choice for tasks where regularization is important.
We set the learning rate to 1e-3 which is a decent setting for small networks. We estimate the loss after every $200$ steps by taking the average to prevent a noisy plot and get a more respresentative, smoother plot. We print out the estimated loss value after every $500$ steps.
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(bigramLM.parameters(), lr=1e-3) # typical bigger sized NNs: Lr=3e-4
# batch_size = 32
# for steps in range(10000): # increase number of steps for good results...
# # sample a batch of data
# xb, yb = get_batch('train')
# # evaluate the loss
# logits, loss = bigramLM(xb, yb) # forward pass
# optimizer.zero_grad(set_to_none=True) # clear accumulated gradients
# loss.backward() # backward pass (backprop: to get gradients)
# optimizer.step() # update parameters
# print(loss.item())
# print('\n')
# print(decode(bigramLM.generate(
# idx = torch.zeros((1, 1), dtype=torch.long),
# max_new_tokens=500)[0].tolist()))
eval_iters = 200
max_iters = 10000
eval_interval = 500
@torch.no_grad() # Disable gradient calculation for this function
def estimate_loss(model):
out = {}
model.eval() # Set model to evaluation/inference mode
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train() # Set model back to training mode
return out
train_losses = []
val_losses = []
epochs = []
# Training
for iter in range(max_iters):
# every once in a while evaluate the loss on train and val sets
if iter % eval_interval == 0:
losses = estimate_loss(bigramLM)
train_losses.append(losses['train'].item())
val_losses.append(losses['val'].item())
epochs.append(iter)
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = bigramLM(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# generate from the model
context = torch.zeros((1, 1), dtype=torch.long)
print(decode(bigramLM.generate(context, max_new_tokens=500)[0].tolist()))
step 0: train loss 4.7344, val loss 4.7194 step 500: train loss 4.3595, val loss 4.3657 step 1000: train loss 4.0399, val loss 4.0333 step 1500: train loss 3.7717, val loss 3.7777 step 2000: train loss 3.5683, val loss 3.5449 step 2500: train loss 3.3609, val loss 3.3738 step 3000: train loss 3.2257, val loss 3.2126 step 3500: train loss 3.0749, val loss 3.0815 step 4000: train loss 2.9614, val loss 2.9752 step 4500: train loss 2.9023, val loss 2.8865 step 5000: train loss 2.8088, val loss 2.8148 step 5500: train loss 2.7477, val loss 2.7657 step 6000: train loss 2.7325, val loss 2.7407 step 6500: train loss 2.6671, val loss 2.6675 step 7000: train loss 2.6437, val loss 2.6664 step 7500: train loss 2.6293, val loss 2.6457 step 8000: train loss 2.6091, val loss 2.6244 step 8500: train loss 2.5660, val loss 2.5657 step 9000: train loss 2.5818, val loss 2.5597 step 9500: train loss 2.5399, val loss 2.5903 Ty whacollo, BSEDJ$ge codry ar ard, PO: Reft ong?Is r onde I y thiefod phe zke w are IUL'Buser IVzzPE: TAy yon ibWu he. WADHatry,SOL: oundes q-w crd Amyse w'therd agn pthes, y andll t dyCK: INOLIfo. Wnonotou, t. G jugh cert ertod'd w'dend, weais gh, t inniso--thmede the w arinowivim'd Yaw tus gmey's: K urdeven mamem, se man s nd grd los whismishenorivpow FC-FL&! u frnlld icy vefre, mu aloct F! tr heeng; brd g THAUMurunis: Tre BARO, m CHe de I wes, tecal l I:er&; st halor RIsh-douerd? I t jXALO:
# Create a figure and axes
fig, ax = plt.subplots(figsize=(8, 6))
# Plot the training and validation losses
ax.plot(epochs, train_losses, label='Training Loss')
ax.plot(epochs, val_losses, label='Validation Loss')
# Set the x-axis and y-axis labels
ax.set_xlabel('Iterations', fontsize=14)
ax.set_ylabel('Loss', fontsize=14)
# Set the x-axis ticks and labels
ax.set_xticks(epochs)
ax.set_xticklabels(epochs, rotation=67.5, fontsize=12)
# Set the y-axis tick format
ax.yaxis.set_major_formatter(plt.FormatStrFormatter('%.1f'))
# Set the title
ax.set_title('Training and Validation Losses', fontsize=16)
# Add a legend
ax.legend(fontsize=12)
# Add grid lines
ax.grid(linestyle='--', alpha=0.5)
# Adjust the spacing between subplots
plt.tight_layout()
# Display the plot
plt.show()

As we increase the number of epochs, our generation begins to resemble Shakespeare format but the text is stil nonsensical.
What are the drawbacks of this model?
Even though it can generate characters based on previous characters, it only takes into account the previous character as the context. It cannot understand the context of grammar rules that emerge over words and sentences.
2. Self-Attention¶
Attention is a communication mechanism that allows models to focus on different parts of the input data when making predictions. This concept is especially important in sequence-based NLP tasks such as machine translation and text summarization, and image processing tasks such as image captioning. It helps models pick out the important bits from a lot of information and focus on them to make smarter decisions. It overcomes the long-range dependency limitations of RNNs & LSTMs by allowing the model to weigh the importance of different elements in the sequence. Instead of processing each element sequentially, attention enables the model to look at all elements simultaneously and decide which ones are more relevant to the current task.
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
Overall, attention is good for capturing long-range dependencies, parallel processing, and making model decisions more interpretable.
2.1. V1: Averaging Past Context with For Loops - Weakest Form of Aggregation¶
We want our tokens to talk to each other. Tokens must talk only with the previous tokens. Since we are predicting the next token, we need to consider the previous tokens only (5th token communicates with 1st, 2nd, 3rd & 4th tokens)
The easiset way to make them communicate is by averaging the previous tokens embeddings. This is a weak form of interaction, it is extremely lossy since we are losing the spatial information of the token arrangements and positions.
# consider the following toy example:
torch.manual_seed(1337)
B,T,C = 4,8,2 # batch, time (tokens or block_size), channels (vocab_size)
x = torch.randn(B,T,C)
print("x:", x.shape, "\n")
# We want x[b, t] = mean_{i <= t} x[b, i]
xbow = torch.zeros((B, T, C)) # Create tensor of zeros of shape (B, T, C) (bag of words representation of the input)
for b in range(B): # For all batches
for t in range(T): # For all tokens in the batch
xprev = x[b, :t+1] # Get all tokens up to and including the current token (t, C)
xbow[b, t] = torch.mean(xprev, 0) # Calculate the mean of the tokens up to and including the current token
print('Batch [0]:\n', x[0], "\n") # First batch of 8 tokens, each of size 2
print('Running Averages:\n', xbow[0]) # Running averages of the first batch of 8 tokens, each of size 2
x: torch.Size([4, 8, 2])
Batch [0]:
tensor([[ 0.1808, -0.0700],
[-0.3596, -0.9152],
[ 0.6258, 0.0255],
[ 0.9545, 0.0643],
[ 0.3612, 1.1679],
[-1.3499, -0.5102],
[ 0.2360, -0.2398],
[-0.9211, 1.5433]])
Running Averages:
tensor([[ 0.1808, -0.0700],
[-0.0894, -0.4926],
[ 0.1490, -0.3199],
[ 0.3504, -0.2238],
[ 0.3525, 0.0545],
[ 0.0688, -0.0396],
[ 0.0927, -0.0682],
[-0.0341, 0.1332]])
For each column, we have vertically averaged at each step from the first step until that current step. We can make this much more efficient using matrix multiplication and removing the for loops.
2.2. Trick: Matrix Multiplication as Weighted Aggregation¶
For each column, we have vertically averaged at each step from the first step until that current step by using torch.tril and matrix multiplication a @ b.
# toy example illustrating how matrix multiplication can be used for a "weighted aggregation"
torch.manual_seed(42)
a = torch.tril(torch.ones(3, 3)) # Lower triangular matrix of ones
a = a / a.sum(dim=1, keepdim=True) # Normalize the matrix by dividing along each row
b = torch.randint(0, 10, (3, 2)).float() # 3x2 matrix of random integers between 0 and 9
c = a @ b # Matrix multiplication of a and b
print('a=')
print(a)
print('--')
print('b=')
print(b)
print('--')
print('c=')
print(c)
a=
tensor([[1.0000, 0.0000, 0.0000],
[0.5000, 0.5000, 0.0000],
[0.3333, 0.3333, 0.3333]])
--
b=
tensor([[2., 7.],
[6., 4.],
[6., 5.]])
--
c=
tensor([[2.0000, 7.0000],
[4.0000, 5.5000],
[4.6667, 5.3333]])
2.3. V2: Matrix Multiplication¶
Now we can use matrix multiplication and the mathematics trick to implement a weighted aggregation.
# version 2: using matrix multiply for a weighted aggregation
wei = torch.tril(torch.ones(T, T))
wei = wei / wei.sum(1, keepdim=True)
wei
# run matrix multiplication in parallel for all B batch elements, each element has (T,T) X (T,C) --> (T,C)
xbow2 = wei @ x # (T, T) @ (B, T, C) ---auto-stride: broadcast--> (B, T, T) @ (B, T, C) ----> (B, T, C)
torch.allclose(xbow, xbow2, atol=1e-7)
True
2.4. V3: Softmax¶
Now let's use softmax to perform weighted aggregation of the preceding tokens. The Softmax approach is preferred due to its accurate representation of the context. By setting upper triangular indices to -inf, we have defined that, the future cannot communicate with the past. We can use a lower triangular matrix to perform weighted aggregation of the past elements.
In a decoder, we implement masked attention in which a token cannot access the weights of future tokens. It can be connected with itself or with past tokens. We cannot aggregate any information from the future tokens.
To implement masking, we use PyTorch's function tril which only returns the lower diagonal of a tensor while the upper diagonal is filled with zeros. With the help of this tensor, we fill the positions that were filled with $0$ with $-\infty$. When we apply softmax across rows to normalize the values, the $-\infty$ is stored as $0$, preserving the masking. Then weights are multiplied by values.
tril = torch.tril(torch.ones(T, T))
tril
tensor([[1., 0., 0., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0., 0., 0.],
[1., 1., 1., 1., 0., 0., 0., 0.],
[1., 1., 1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1., 1., 1.]])
wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei
tensor([[0., -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0., 0., 0., 0.]])
wei = torch.zeros((T,T)) # Lower triangular matrix of ones
wei = wei.masked_fill(tril == 0, float('-inf')) # Replace all the elements of wei where tril == 0 with -inf
wei = F.softmax(wei, dim=-1) # Apply softmax to the wei tensor along the last dimension (rows) (dim=-1)
wei
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5000, 0.5000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3333, 0.3333, 0.3333, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2500, 0.2500, 0.2500, 0.2500, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2000, 0.2000, 0.2000, 0.2000, 0.2000, 0.0000, 0.0000, 0.0000],
[0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.0000, 0.0000],
[0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.0000],
[0.1250, 0.1250, 0.1250, 0.1250, 0.1250, 0.1250, 0.1250, 0.1250]])
# version 3: use Softmax
tril = torch.tril(torch.ones(T, T))
wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
# wei
xbow3 = wei @ x
torch.allclose(xbow, xbow3, atol=1e-7)
True
2.5. Bigram LM Code Tweaks: Robust Token Embedding Dimension¶
Now, we can make a few changes and cleanups to our script. Let's introduce a new n_embd variable to the embedding table. Our embedding lengths might differ from the vocab_size. However, now the embedding table won't give us logits directly and generate tokens. We must introduce an intermediary linear layer to go from embeddings to the logits.
2.6. Bigram LM Code Tweaks: Positional Encoding¶
Until now, we only defined identity embeddings. Embeddings do not change with the position. However, positional information is also important. Thus, we will define a position embedding table. However, in a bigram model, this means little, due to the small context size.
In Sections $2.5$ & $2.6$, we've implemented multiple changes to our BigramLanguageModel(nn.Module) class.
__init__now takes no arguments (vocab_sizeis now a global variable)- Intermediate phase added before logit embedding:
- Changed embedding layer dimensions from
(vocab_size, vocab_size)to(vocab_size, n_embd)n_embdis the now arbitrary size of the vector into which the token is embedded
- Added a linear layer
self.lm_headfor the logit embedding of dimensions(n_embd, vocab_size)so that we can do the weighted aggregation of the past tokens with size(n_embd, n_embd)
- Changed embedding layer dimensions from
- Added positional embeddings
- positional embedding layer of dimensions
(block_size, n_embd), embeds the token position in the sequence pos_embis the positional embedding of the current token, which is added (+) to the embedding of the current token informationtok_emb- this sum is then passed to the linear layer to get the
logits
- positional embedding layer of dimensions
So at this point linear layer input holds not just the token identities, but the positions at which these tokens occur. This is currently not that useful because of course, we just have a simple bigram model. So it doesn't matter if you're in the $5\text{th}$ position, the $2\text{nd}$ position or wherever, it's all translation invariant at this stage. So this information currently wouldn't help. But as we work on the self-attention block, we'll see that this starts to matter.
In summary, these minor code changes do not yet affect anything, because we are still missing the self-attention block. However, the model works still.
Aside: translation invariance means that the system can recognize an object or pattern in an image regardless of its position.
import torch.nn as nn
class BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd) #new positional embedding table
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, targets=None):
# idx and targets are both (B,T) tensor of integers
B, T = idx.shape
tok_emb = self.token_embedding_table(idx)
pos_emb = self.position_embedding_table(torch.arange(T, device = device)) #(T, C)
x = tok_emb + pos_emb # add the positional tokens
logits = self.lm_head(x)
if targets is None: # don't compute loss if targets not given (used for generation)
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C) # (B x T, C)
targets = targets.view(B*T) # (B x T)
loss = F.cross_entropy(logits, targets) # F.cross_entropy inputs shape (B, C, T)
return logits, loss
2.7. V4: SELF-ATTENTION¶
Now let's use self-attention to perform weighted aggregation of the preceding/past tokens. We'll build a self-attention unit for a single head to understand how attention works in the simplest case.
Self-attention is the part of the model where tokens interact with each other. Each token "looks" at other tokens in the sentence with an attention mechanism, gathers context, and updates the previous representation of "self". Let's look at the illustration below (Note that in practice, this happens in parallel.).
# @title
from IPython.display import HTML, Video
video_url = "https://lena-voita.github.io/resources/lectures/seq2seq/transformer/encoder_self_attention.mp4"
video_html = f"""
<video width="720" height="400" controls loop muted autoplay>
<source src="{video_url}" type="video/mp4">
Your browser does not support the video tag.
</video>
"""
HTML(video_html)
Query, Key, and Value in Self-Attention¶
Formally, this intuition is implemented with a query-key-value attention. Each input token in self-attention receives three representations corresponding to the roles it can play:
- Query - asking for information;
- Key - saying that it has some information;
- Value - giving the information.
The query is used when a token looks at others - it's seeking the information to understand itself better. The key is responding to a query's request: it is used to compute attention weights. The value is used to compute attention output: it gives information to the tokens which "say" they need it (i.e. assigned large weights to this token).
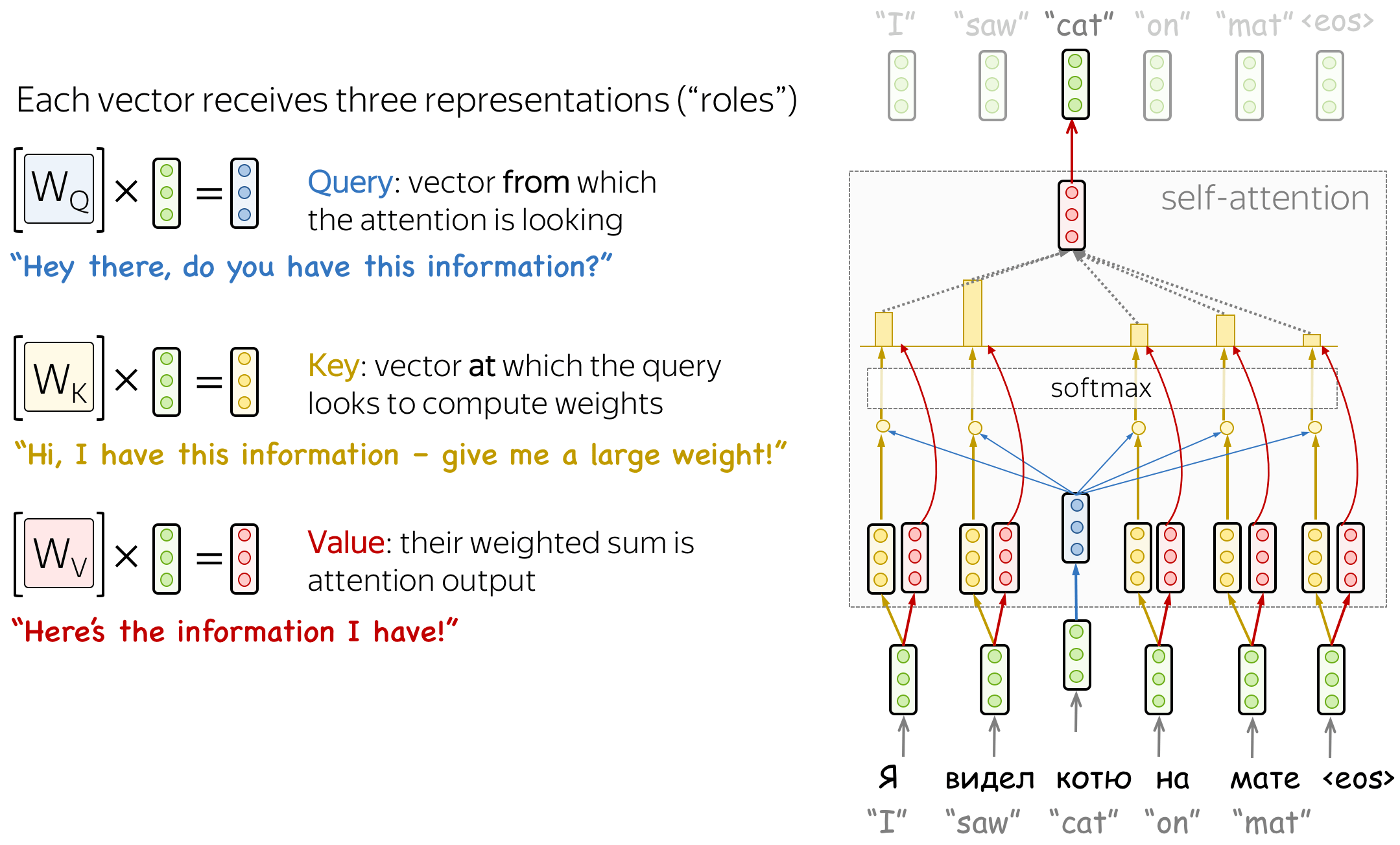
Figure 1: Query, Key, Value in Self-Attention Explained. (Source)
We call our particular attention “Scaled Dot-Product Attention”. The input consists of queries and keys of dimension $d_k$, and values of dimension $d_v$. We compute the dot products of the query with all keys, divide each by $\sqrt{d_k}$, and apply a softmax function to obtain the weights on the values.

Figure 2: Scaled Dot-Product Attention. (Source)
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix $Q$. The keys and values are also packed together into matrices $K$ and $V$. The softmax outputs are known as the attention weights or affinity matrix. We compute the matrix of attention outputs as:
$$ {\text{Attention}}(Q, K, V) = \text{softmax}(\frac{QK^{T}}{\sqrt{d_k}})V $$
According to The Annotated Transformer article, the two most commonly used attention functions are additive, and dot-product (multiplicative) attention. In our case, we employed a scaled version (scaling factor of $\frac{1}{d_k}$) of dot-product attention. Both methods are similar in theretical complexity, however dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
While for small values of ${d_k}$ the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of ${d_k}$. We suspect that for large values of ${d_k}$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. Let's illustrate why the dot products get large. If we assume that $q$ and $k$ are ${d_k}$-dimensional vectors whose components are independent random variables with mean $0$ and variance $1$. Then their dot product, $q \cdot k = \sum_{i=1}^{d_k} q_ik_i$, has mean $0$ and variance $d_k$. To counteract this effect for large values of ${d_k}$ (since we would prefer these values to have variance $1$), we scale the dot-product by $\frac{1}{\sqrt{d_k}}$.
We build a self-attention block for a single, individual head for simplicity. To do that, we'll continue with our 'running average' trick from before. I already hinted at it: We don't want the probabilities of wei to be row-wise uniform.
Different tokens should find other tokens more or less important/interesting, and this should be learned by the model.
Gather information from the past, but do so in a data-dependent way and improve based on training.
With Self-Attention, every single token in the batch emits two vectors: query and key:
- The
queryvector is the token-specific "What am I looking for?" information - The
keyvector is the token-specific "What do I contain?" information
To establish affinity (high interrelation and high influence on the sampling decision) between tokens of the batch, we calculate the dot product of the query and key vectors of each token with each other token in the batch.
This is the affinity matrix or in our case wei.
If during dot product calculation the key and the query turn out to be well aligned or similar, the affinity will be high. If they are not, the affinity will be low.
Let's build the individual head:
# version 4: self-attention!
torch.manual_seed(1337)
B,T,C = 4,8,32 # batch, time, channels
x = torch.randn(B,T,C)
# let's see a single Head perform self-attention
head_size = 16
key = nn.Linear(C, head_size, bias=False)
query = nn.Linear(C, head_size, bias=False)
value = nn.Linear(C, head_size, bias=False)
k = key(x) # (B, T, 16)
q = query(x) # (B, T, 16)
wei = q @ k.transpose(-2, -1) # (B, T, 16) @ (B, 16, T) ---> (B, T, T)
tril = torch.tril(torch.ones(T, T))
#wei = torch.zeros((T,T))
wei = wei.masked_fill(tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
v = value(x)
out = wei @ v
#out = wei @ x
out.shape
torch.Size([4, 8, 16])
wei[0]
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1574, 0.8426, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2088, 0.1646, 0.6266, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5792, 0.1187, 0.1889, 0.1131, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0294, 0.1052, 0.0469, 0.0276, 0.7909, 0.0000, 0.0000, 0.0000],
[0.0176, 0.2689, 0.0215, 0.0089, 0.6812, 0.0019, 0.0000, 0.0000],
[0.1691, 0.4066, 0.0438, 0.0416, 0.1048, 0.2012, 0.0329, 0.0000],
[0.0210, 0.0843, 0.0555, 0.2297, 0.0573, 0.0709, 0.2423, 0.2391]],
grad_fn=<SelectBackward0>)
2.8. $6$ Key Notes on Attention¶
Notes:
- Attention is a communication mechanism. It can be seen as nodes in a directed graph looking at each other and aggregating information with a weighted sum from all nodes that point to them, with data-dependent weights.
- It contains a directed graph and each node aggregates information via a weighted sum of the nodes pointed towards it. This is done in a data-dependent manner.
- Attention does not have a notion of space. It simply acts over a set of vectors. This is why we need to positionally encode tokens.
- Thus, we have to encode the node positionally, which was done through a positional encoding. In contrast, convolutional mechanisms have a concrete layout of information in the space. There is no notion of space.
- There is no communication across batch dimension.
- Each example across batch dimension is of course processed completely independently and never "talk" to each other.
- In an "encoder" attention block, it justs delete the single line that does masking with
tril, allowing all tokens to communicate. The masking block here is called a "decoder" attention block because it has triangular masking, and is usually used in autoregressive settings, like language modeling.- In some cases, we must allow every node to talk to each other. (Ex: Sentiment analysis, the process of analyzing digital text to determine the emotional tone of a message). Thus, we will use an encoder block of self-attention. It simply deletes the lower triangular mask step and lets all the nodes communicate. In decoder blocks, future nodes will never communicate with the current node as masking step is active.
- "self-attention" just means that the keys and values are produced from the same source as queries. In "cross-attention," the queries still get produced from x, but the keys and values come from some other, external source (e.g. an encoder module)
- Our implementation is called self-attention since both keys, queries, and values are coming from the same source, thus the nodes are self-attending. In cross-attention, keys and values might be generated from a different set of nodes.
- "Scaled" self-attention additional divides
weiby 1/sqrt(head_size). This makes it so when input Q,K are unit variance, wei will be unit variance too and Softmax will stay diffuse and not saturate too much. Illustration below- In the ‘Attention is all you need’ paper, the attention weights are divided by $\sqrt{head\_size}$. This will allow
weito have a unit variance. This is important since wei is fed to a softmax layer. Ifweihave large positive or negative numbers during the initialization, the softmax will be converged to one-hot vectors.
- In the ‘Attention is all you need’ paper, the attention weights are divided by $\sqrt{head\_size}$. This will allow
k = torch.randn(B, T, head_size)
q = torch.randn(B, T, head_size)
wei = q @ k.transpose(-2, -1)
print("Unscaled Dot-Product Self-Attention")
print(k.var().item().__format__('.4f'))
print(q.var().item().__format__('.4f'))
print(wei.var().item().__format__('.4f')) # The variance is larger
wei = q @ k.transpose(-2, -1) * (head_size ** -0.5) # This is the scaled attention, avoiding exploding variance which would sharpen the softmax distributions (and thus make the attention more deterministic)
print("\nScaled Dot-Product Self-Attention")
print(k.var().item().__format__('.4f')) # The variance is like before
print(q.var().item().__format__('.4f')) # The variance is like before
print(wei.var().item().__format__('.4f')) # The variance is now much smaller
Unscaled Dot-Product Self-Attention 1.0449 1.0700 17.4690 Scaled Dot-Product Self-Attention 1.0449 1.0700 1.0918
torch.softmax(torch.tensor([0.1, -0.2, 0.3, -0.2, 0.5]), dim=-1)
tensor([0.1925, 0.1426, 0.2351, 0.1426, 0.2872])
torch.softmax(torch.tensor([0.1, -0.2, 0.3, -0.2, 0.5])*8, dim=-1) # gets too peaky, converges to one-hot
tensor([0.0326, 0.0030, 0.1615, 0.0030, 0.8000])
3.1. Single Self-Attention¶
Now let's build a single self-attention block. During initialization, just like we discussed in self-attention, we initialize the key, query, and value vector to have the dimensions of n_embd embeddings and head_size
So the input vectors would be inputted with B, T, C dimensions:
[Batch, Time (block size) and Channels (embedding dimensions)]
and their key, query, and value vectors would be taking in the C dimension (n_embd) and multiplying with head_size.
In self.register_buffer(torch.tril(torch.ones(block_size, block_size))) we use register_buffer to register a tensor as part of a module's state, but not as a parameter to be optimized during training. This is typically used for tensors that you want to keep track of but don't want to optimize. The tril vector will be used for masking.
The nn.Dropout randomly drops some neurons in a layer which means it initializes them as zero during every forward and backward pass to prevent overfitting of data and building an ensemble of neural networks.
In the forward function, we calculate attention similar to how we did in the previous section. The only addition is that we scale the weights by dividing them by the square root of the dimension of the key vector, to implement scaled dot product attention. Scaling it with the square root ensures that it has a unit Gaussian distribution which makes training easier.
The rest should be recognizable from the Section 2.7.
class Head(nn.Module):
""" one head of self-attention """
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# input of size (batch, time-step, channels)
# output of size (batch, time-step, head size)
B,T,C = x.shape
k = self.key(x) # (B,T,hs)
q = self.query(x) # (B,T,hs)
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * k.shape[-1]**-0.5 # (B, T, hs) @ (B, hs, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the values
v = self.value(x) # (B,T,hs)
out = wei @ v # (B, T, T) @ (B, T, hs) -> (B, T, hs)
return out
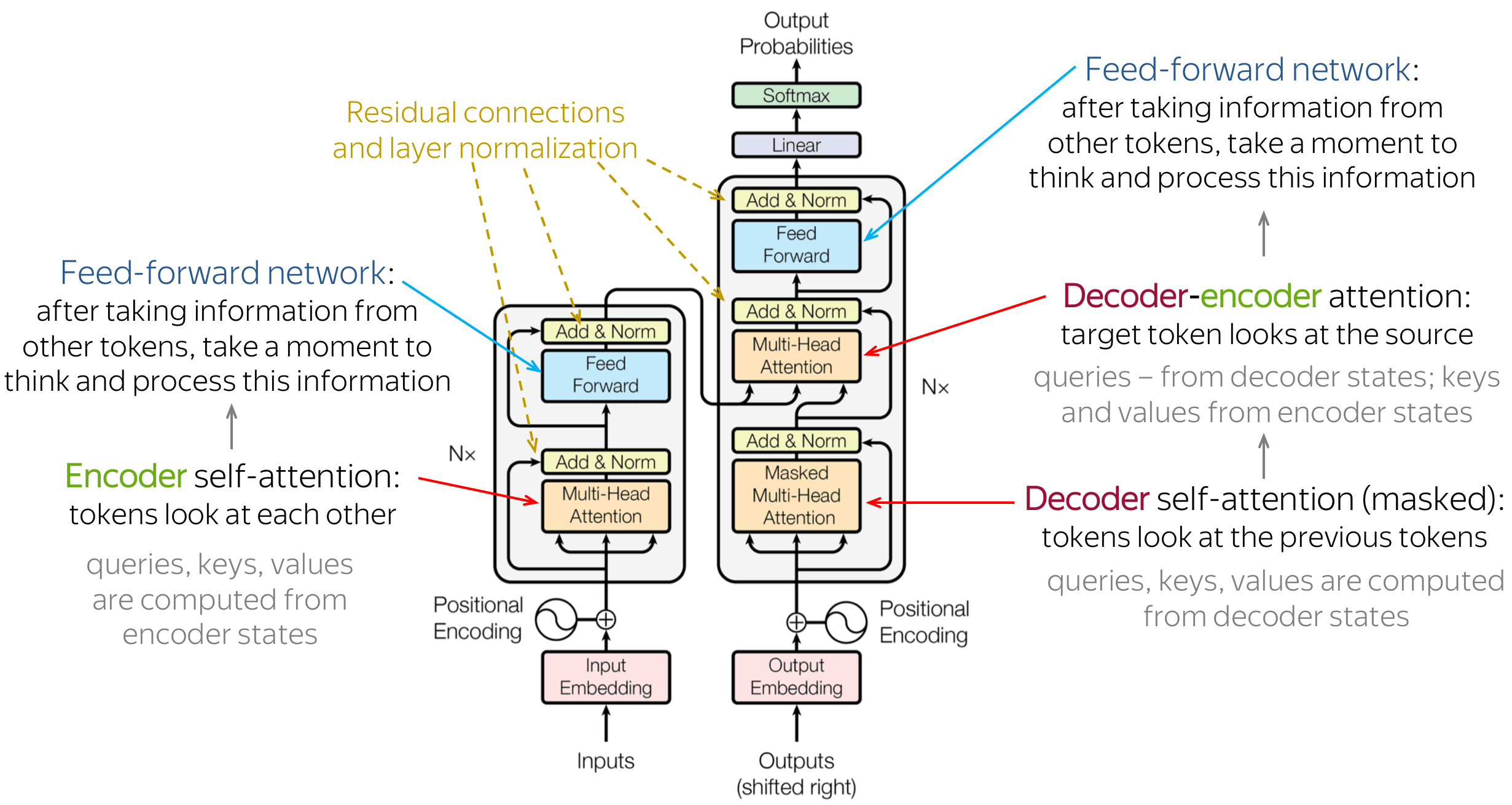
3.2. Multi-Head Attention (MHA)¶
Multi-head attention:
This is applying multiple attentions in parallel
and concatenating the results.It's basically just multiple attentions in parallel. Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
$$\text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1, \text{...}, \text{head}_h )W^O$$ $$\text{where }\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)$$
Where the projections are parameter matrices:
$$W_i^Q \in \mathbb{R}^{ d_{model} \times\ {d_K} }$$ $$W_i^K \in \mathbb{R}^{ d_{model} \times\ {d_K} }$$ $$W_i^V \in \mathbb{R}^{ d_{model} \times\ {d_V} }$$ $$W_i^O \in \mathbb{R}^{ hd_v \times\ d_{model}}$$ $$ \text{with } {d_k} = {d_v} = d_{model}/h $$

Figure 4: Multi-Head Attention. (Source)
Let's implement a multi-head attention block.
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embd, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
3.3. Feed-Forward Network (FFN)¶
Feed-forward network (FFN):
This is basically two linear transformations with a ReLU activation in between.
$\text{FFN}(x) = \text{max}(0, xW_1 + b_1)W_2 + b_2$
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as $2$ convolutions with kernel size $1$.
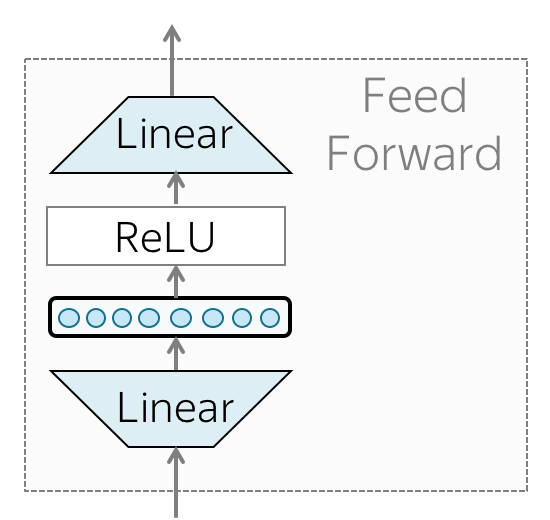
Figure 5: Feed-Forward Network. (Source)
Next, let's add a feed-forward network, which is basically a simple multilayer perceptron network.
class FeedFoward(nn.Module):
""" a simple linear layer followed by a non-linearity """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, n_embd),
nn.ReLU(),
nn.Linear(n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
We were too fast to calculate the logits. With multi-head-attention, we allowed the nodes to collect all the information they needed but we did not allow them to "think." Thus, the feed-forward network layer allows the model tokens to "think"/process the data individually & independently.
3.4. Residual Connections¶
We have already implemented most of all the necessary building blocks for the transformer architecture. Now it is time to collect them together. Now we can define a block module, which intersperses all the communications and computations. Communication between the nodes will be done via the multi-head self-attention and token-level computations will be done using the feed-forward network. This implementation does not significantly improve the performance. The neural network has become deeper. However, deeper neural networks suffer from optimization issues.
The first solution for the issue is using residual connections.
Residual Connections:
Residual Connections are a type of skip-connection that learn residual functions with reference to the layer inputs, instead of learning unreferenced functions. They are very simple (add a block's input to its output), but at the same time are very useful: they ease the gradient flow through a network and allow stacking of multiple layers. The intuition is that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers. Having skip connections allows the network to more easily learn identity-like mappings.
Formally, denoting the desired underlying mapping as , let the stacked nonlinear layers fit another mapping of $F(x) := H(x) - x = \text{output} - \text{input}$
The original mapping is recast into $F(x) + x$.
$F(x)$ acts like a residual, hence the name "residual block."
According to an article on residual blocks, our residual block is overall trying to learn the true output, H(x). If you look closely at the image above, you will realize that since we have an identity connection coming from x, the layers are actually trying to learn the residual, F(x). So to summarize, the layers in a traditional network are learning the true output (H(x)), whereas the layers in a residual network are learning the residual (F(x)). Hence, the name: Residual Block.

Figure 6: Residual Block: (1)-Residual Connection on the Side of the Layer, (2)-Layer on the Side of the Residual Connection. (Source)
In the $2$nd figure above on the right, the computation follows a residual pathway with addition operations connecting the inputs to the targets. The residual pathway allows intermediate computations to fork off and rejoin through addition. This residual design allows gradients during backpropagation to flow unimpeded from the loss all the way to the inputs via the addition operations, creating a "gradient superhighway." The residual blocks are initially initialized to contribute very little, essentially bypassing them at first. However, during training, these residual blocks gradually come online (into play) and start contributing to the computation & improving the optimization. This architecture helps optimize the model effectively by enabling direct and unobstructed gradient flow initially, while allowing the residual blocks to adapt and contribute over time. The combination of the residual pathway and the gradual incorporation of residual blocks dramatically improves the optimization process.
Another article states that residual connection is when we add identity mapping in addition to the output before passing it to the next layer. This is another way of saying that we add the input to the output before passing it onto the next layer. This solves the problem of exploding or vanishing gradients seen in feed-forward neural networks because in these networks the path length for output is proportional to the number of layers. On adding more layers, the gradient explodes because the resultant output is huge compared to the outputs of neurons in the initial layers. This makes the network during backpropagation unstable.
Next, let's construct our block module.
class Block(nn.Module):
""" Transformer block: communication followed by computation """
def __init__(self, n_embd, n_head):
# n_embd: embedding dimension, n_head: the number of heads we'd like
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
3.5. Layer Normalization (LayerNorm)¶
LayerNorm helps us to optimize our network even more via normalizing the activations of the neurons withing a layer. It is similar to batchNorm which we've encountered previously. Unlike batchNorm which normalizes across the batch dimension (columns), LayerNorm normalizes across the features in a layer (rows).
Unlike batch normalization, Layer Normalization directly estimates the normalization statistics from all of the summed inputs to the neurons within a hidden layer so the normalization does not introduce any new dependencies between training cases. Unlike batch normalization, layer normalization performs exactly the same computation at training and test times. It is also straightforward to apply to recurrent neural networks by computing the normalization statistics separately at each time step. Layer normalization is very effective at stabilizing the hidden state dynamics in recurrent networks.
We compute the layer normalization statistics over all the hidden units in the same layer as follows: $$\mu^l = \frac{1}{H}\sum_{i=1}^H a_i^l$$ $$ $$ $$\sigma^l = \sqrt{\frac{1}{H}\sum_{i=1}^H (a_i^l - \mu^l)^2}$$

Figure 7: Layer Normalization. (Source)
# Makemore 3's BatchNorm1d
class BatchNorm1d:
def __init__(self, dim, eps=1e-5, momentum=0.1):
self.eps = eps # Epsilon set to PyTorch default, you may change it
self.momentum = momentum # Momemtum set to PyTorch default, you may change it
self.training = True
# Initialize Parameters (trained with backprop)
# (bngain -> gamma, bnbias -> beta)
self.gamma = torch.ones(dim)
self.beta = torch.zeros(dim)
# Initialize Buffers
# (Trained with a running 'momentum update')
self.running_mean = torch.zeros(dim)
self.running_var = torch.ones(dim)
def __call__(self, x):
# Forward-Pass
if self.training:
xmean = x.mean(0, keepdim=True) # Batch mean
xvar = x.var(0, keepdim=True) # Batch variance
else:
xmean = self.running_mean # Using the running mean as basis
xvar = self.running_var # Using the running variance as basis
# Normalize to unit variance
xhat = (x - xmean) / torch.sqrt(xvar + self.eps)
self.out = self.gamma * xhat + self.beta # Apply batch gain and bias
# Update the running buffers
if self.training:
with torch.no_grad():
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * xmean
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * xvar
return self.out
def parameters(self):
return [self.gamma, self.beta] # return layer's tensors
torch.manual_seed(1337)
module = BatchNorm1d(100)
x = torch.randn(32, 100) # Batch size 32, 100 features (batch size 32 of 100-dimensional vectors)
x = module(x) # Forward pass
print("\nBatch Normalization down the columns")
print(x[:,0].mean(), x[:,0].std()) # mean and standard deviation of the 1st feature across all batch inputs (columns)
print("\nBatch Normalization across the rows")
print(x[0,:].mean(), x[0,:].std(),'\n') # mean and standard deviation of a single input (1st one) from the batch (rows)
print(x[:5,0]) # See how the feature indicates the normalization feature-wise across the batch, not sample-wise across the features
print(x.shape) # Output shape should is the same as input shape
Batch Normalization down the columns tensor(7.4506e-09) tensor(1.0000) Batch Normalization across the rows tensor(0.0411) tensor(1.0431) tensor([ 0.0468, -0.1209, -0.1358, 0.6035, -0.0515]) torch.Size([32, 100])
To implement LayerNorm, we need to normalize the samples across the features (rows). So we change the dimension of the mean and standard deviation for xmean and xvar respectively in batchNorm above:
xmean = x.mean(1, keepdim=True) # Layer mean
xvar = x.var(1, keepdim=True) # Layer variance
Because the calculations inside LayerNorm don't span across the batch dimension, we can remove the buffers running_mean and running_var. There also is no distinction between training and eval mode anymore. We can remove the train parameter. The training process will determine the deviation from the unit gaussian distribution as seen fit by the optimizer.
With the changes in place, we can now add LayerNorm to the model.
class LayerNorm1d: # (used to be BatchNorm1d)
def __init__(self, dim, eps=1e-5):
self.eps = eps
self.gamma = torch.ones(dim)
self.beta = torch.zeros(dim)
def __call__(self, x):
# calculate the forward pass
xmean = x.mean(1, keepdim=True) # batch mean
xvar = x.var(1, keepdim=True) # batch variance
xhat = (x - xmean) / torch.sqrt(xvar + self.eps) # normalize to unit variance
self.out = self.gamma * xhat + self.beta
return self.out
def parameters(self):
return [self.gamma, self.beta]
torch.manual_seed(1337)
module = LayerNorm1d(100)
x = torch.randn(32, 100) # batch size 32 of 100-dimensional vectors
x = module(x)
print("x:", x.shape)
print("\nLayer Normalization down the columns")
print(x[:,0].mean(), x[:,0].std()) # mean,std of one feature across all batch inputs
print("\nLayer Normalization across the rows")
print(x[0,:].mean(), x[0,:].std()) # mean,std of a single input from the batch, of its features
x: torch.Size([32, 100]) Layer Normalization down the columns tensor(0.1469) tensor(0.8803) Layer Normalization across the rows tensor(-9.5367e-09) tensor(1.0000)
Note that we deviate from the original paper in our implementation of LayerNorm in our network.
In the "attention is all you need" paper, Add+Norm is applied after the transformation (FFN, MHA). However recently, it is a bit more common to apply the LayerNorm before the transformation, instead of after. This is because the LayerNorm is more expensive than the transformation. We want to apply the LayerNorm as early as possible, so that we can skip it in the residual connection if the transformation is skipped. This is called "pre-norm" formulation.
3.6. Scaling Up the Model¶
Let's add a dropout layer right before the residual connection. Dropout is a regularization technique for neural networks that drops a unit (along with connections) at training time with a specified probability $p$ (a common value is $p$ = 0.5). At test time, all units are present, but with weights scaled by $p$ (i.e. $w$ becomes $pw$).
The idea is to prevent co-adaptation, where the neural network becomes too reliant on particular connections, as this could be symptomatic of overfitting. Intuitively, dropout can be thought of as creating an implicit ensemble of sub-neural networks.

Figure 8: Dropout. (Source)
Now we have a pretty complete transformer, but it is a decoder-only transformer unlike the one in the Attention paper. It is a decoder-only transformer because we implemented triangular masking on our affinity weights prior to applying softmax on them to ensure auto-regressive property. Also, our transformer block has only self-attention and no cross-attention.
Let's increase some of the hyperparameters since we're running the model on a GPU.
# hyperparameters
batch_size = 64 # how many independent sequences will we process in parallel?
block_size = 256 # what is the maximum context length for predictions?
max_iters = 5000
eval_interval = 500
learning_rate = 3e-4 #1e-3 #1e-2
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 384 # (n_head * batch_size)
n_head = 6 # (n_embd/batch_size)
n_layer = 6
dropout = 0.2
3.7. Putting It All Together¶
Let's put all the code together to run as one cohesive transformer language model (GPT). The validation loss reduces from $\boldsymbol{2.5903}$ in the simple baseline bigram language model (LM) to $\boldsymbol{1.4856}$ in the GPT language model. The generated text is now fully structured as a Shakespearan work (script dialogue format with text broken up into different character's dialogue parts). Most of the words and punctuations are consistent with proper English. There are still some nonsensical words and phrases but overall it's better than the generated text from the simple bigram LM.
The figure below is a model architecture for the $\boldsymbol{6}$-layer ($\boldsymbol{N} = 6$) decoder transformer (GPT) built in this section.
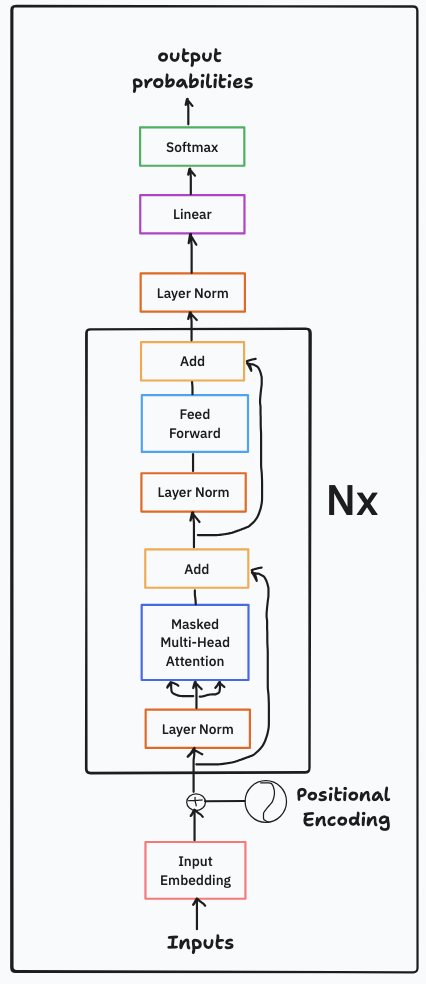
Figure 9: Decoder Transformer (GPT) Model Architecture.
# hyperparameters
batch_size = 64 #16 #32 how many independent sequences will we process in parallel?
block_size = 256 #32 #8 what is the maximum context length for predictions?
max_iters = 5000 #3000
eval_interval = 500 #300
learning_rate = 3e-4 #1e-3 #1e-2
device = 'cuda' if torch.cuda.is_available() else 'cpu'
eval_iters = 200
n_embd = 384 #64 #32 (n_head * batch_size)
n_head = 6 #4 (n_embd/batch_size)
n_layer = 6 #4
dropout = 0.2 #0.0
# ------------
torch.manual_seed(1337)
# !wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
# with open('input.txt', 'r', encoding='utf-8') as f:
# text = f.read()
<torch._C.Generator at 0x7e09e0495db0>
# here are all the unique characters that occur in this text
chars = sorted(list(set(text)))
vocab_size = len(chars)
# create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
# Train and test splits
data = torch.tensor(encode(text), dtype=torch.long)
n = int(0.9*len(data)) # first 90% will be train, rest val
train_data = data[:n]
val_data = data[n:]
# data loading
def get_batch(split):
# generate a small batch of data of inputs x and targets y
data = train_data if split == 'train' else val_data
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
x, y = x.to(device), y.to(device)
return x, y
@torch.no_grad()
def estimate_loss():
out = {}
model.eval()
for split in ['train', 'val']:
losses = torch.zeros(eval_iters)
for k in range(eval_iters):
X, Y = get_batch(split)
logits, loss = model(X, Y)
losses[k] = loss.item()
out[split] = losses.mean()
model.train()
return out
class Head(nn.Module):
""" one head of self-attention """
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B,T,C = x.shape
k = self.key(x) # (B,T,C)
q = self.query(x) # (B,T,C)
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei) # randomly prevent some of the nodes from communication
# perform the weighted aggregation of the values
v = self.value(x) # (B,T,C)
out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)
return out
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embd, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
class FeedFoward(nn.Module):
""" a simple linear layer followed by a non-linearity """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
class Block(nn.Module):
""" Transformer block: communication followed by computation """
def __init__(self, n_embd, n_head):
# n_embd: embedding dimension, n_head: the number of heads we'd like
super().__init__()
head_size = n_embd // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.ffwd = FeedFoward(n_embd)
self.ln1 = nn.LayerNorm(n_embd)
self.ln2 = nn.LayerNorm(n_embd)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.ffwd(self.ln2(x))
return x
class GPTLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
self.position_embedding_table = nn.Embedding(block_size, n_embd)
self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd) # final layer norm
self.lm_head = nn.Linear(n_embd, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx and targets are both (B,T) tensor of integers
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
x = self.blocks(x) # (B,T,C)
x = self.ln_f(x) # (B,T,C)
logits = self.lm_head(x) # (B,T,vocab_size)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# crop idx to the last block_size tokens
idx_cond = idx[:, -block_size:]
# get the predictions
logits, loss = self(idx_cond)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
torch.manual_seed(1337)
model = GPTLanguageModel()
m = model.to(device)
# print the number of parameters in the model
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for iter in range(max_iters):
# every once in a while evaluate the loss on train and val sets
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# generate from the model
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=10000)[0].tolist()))
10.788929 M parameters step 0: train loss 4.2849, val loss 4.2823 step 500: train loss 2.0119, val loss 2.0984 step 1000: train loss 1.5956, val loss 1.7743 step 1500: train loss 1.4398, val loss 1.6369 step 2000: train loss 1.3404, val loss 1.5664 step 2500: train loss 1.2798, val loss 1.5329 step 3000: train loss 1.2252, val loss 1.5036 step 3500: train loss 1.1840, val loss 1.4878 step 4000: train loss 1.1461, val loss 1.4820 step 4500: train loss 1.1105, val loss 1.4804 step 4999: train loss 1.0777, val loss 1.4856 A women body! O hay more spide nemble, in loving with thine Should volum holock, when us, young Marcius, upon thy Reason a mable. FRIAR LAURENCE: What then should be less you are, And got upon this happiers' fand by discondested: Once so clothes, for thou vile friar, Go, and make, when my old man Ares, thy strict, And thy spirits are to greet some great Leontant, A sistrainety, ouble sue o' the airing the stars, The glasselsmen will both as the fale, hell tears: Go see thou, passing, the throne convertier'd with thee From the far of Freeder peat, That encous practise to the people! Hold Saint Gaunt Alban'stors with a mirror, A drescueler his son, testing them, Floring of the dearest kind him too the general; he long his hands And heart as halt slow more alreads; he will not his fond: Therefore, from whom lights that hast been i' the crown? Nurse: Thee true? JULIET: He heare times heart enough. Have been Rersolved with our notic! ROMEO: Like him: but saft, fair far both: hence he is. A, fish, what art thou? What shalt thou? Best, thou news him! From so will quickled fail himself; not sterves Pretty too servent as in elsmasterate to-day, Which now ceners and leasts that tumb march to none; But what craws like unto me intell, who should noughts; now now doon the strength we comes Strencely to great it, but it is the susanger, Like to me wide all night him. Please yourself. Second Murderer: Stay, in this Thomaster attenders of him? Second Gentleman: Northumous, what news are that husband, couldry be pray. Turn: Jed me but it by, amended, the rogue is seen: While to this worldly about me? how a fetch the sweetest let thou us? Second Gaunt: I am the neighby say, you might not, Out in o' the young. Go, on 't.' good gentleman: Your entertaince is no charge; and then, are complain in this lerry browledge and leften me cousin, That some some impassion, as often numbers of your Do y kill formers, him to all another to you: The gods will not your mothers will, upon! The argue now, now goes this all to you, ISABELLA: That thou, Han. Provost: ISABELLA: Pray, O, sir, ye! AUTOLYCUS: I thank youself you. DUKE VINCENTIO: But here is respected memodst the make, sir. LUCIO: Rave pipe, as it is she will not be streng: I had ready achamed all the bab! Anothor now, it were friar, my ungrave to me. LUCIO: No, for I think, I know not, sir. For my name hum. Your voice, good man, I loving, to your promiself, as you hundred with me; I hope to serve my father Gloucester ThrigS stand, after to the flatterer of Capulet, And be boar, follow as mind, when it was it penalt My stain'd in hope to the sweet sorrow. AUTOLYCUS: Yet, gentle Marsin; make short. She Prince Earch is, heavenly and yond so, Wadow, whom I have, thy love and dear in Romeo? Servant: Ay, but have been some caps to your good accuse. How found you with so? SICINIUS: I would do thou see how, not thou do me condect? O, how mecure' 'Fretty.' He is thy lance; when Romeo is gone inclination; It kind, eccossion, sufficer sure! have them it do said, that we knew'd the name of him, call the shall ple no haste-slaying: but least, I am a boast too, letter all in like Kather, be known'd and filling Rhmans, and raisety art upon this state; and go now the king, wherein wears I grant wherein say the clouds forse by day'st those he will set with the herd. Seven have the namity has speen timal word. Thy father calothers in them can, though against thou, wouldst not see you to fell upon the dog, Or cozardon to eurtgeous day, I conjurancely. DUCHESS OF YORK: Fear well; and no impasson of evencour! QUEEN MARGARET: Of mouths of thine peace time haste, so deceit should fear his feeling, 'foren haim. QUEEN ELIZABETH: Say, I beseech you, look me son; for your father To little less as you. I fearly of that Because which seems you tales against their Marcient Paris. RIVERS: You did not see, madam; I swear you freel see-. Come to this vision! By now, we may; the news, O, and you! My gracious desire again. Camillor, good friar: there be heard; his on not the powdrokes, worse love, the's pleasure was a duke. As he has straints; commend as he that to's as he task. DUKE VINCENTIO: Why, sister. My husband was I am gone, how I to say! LUCIO: You will buy that hope I have; not this violent he sworn men bittters; and all this garden, all do the duke. Come withal: come to grow in fast, and this offens? No more there, poor are hour, that we have pawn so or murder, and but see: this so your behind, fell you to do prital, I have beg the stroke that odds thee now how. Second Servingman: You know the friar is pate: I do beseech you; Why accompany hath a tribune ma givine; my justify, maffles-- Romeo, to speak stand, strike fury! Take sweet is eaven to a man-on; an't--hating the swear A good grave villains: His youl named is your Will not call him as Southam Letimal. CAMILLO: Grim Tranio, put not a' patricianst the cherinal. Fleet in this bosost Graciost fellow that rags, presssing his crown, His fairful forms great that once and the traitor That he speaks from the head of from Berkn's grace: And, Taluer, son thy complation shall stay Would every bench'd attempt our to terms? FORIZEL: And far a heart for fail men's treasure, as Culll in as betry; or his fifts, sir. SAMPSON: Know you be your daughter'd? The hrismest resay with him And trespass murder, as trust as no losp The Rightstoments are leave by his punishment: Unzrital respect as my poor many grew. THOMAS Oxfords, Gremio, if we appeach call'd, heart 'greetings your honours, he smile earth; A envious wife, my brother kneels it not Your flooks trod politify us and this sill. GLOUCESTER: Then, go we call your grace in resolution The holesons of Rome. LARTIUS: Upon you yet? MAMILLIUS: Here were this dod. LEONTES: I will. Alas, or bitters, I can you taste, boy! PARIS: Put them you shake us worn you, my knees come with To come an easy take hearends: great like, they live me To forewarn put like her life do dexchange Must be so: I shall, as I should hide as his kind, From my body scorn o'ertast lips to get in: And I, thence, for I careleft be grief, Uncertain to him came be quickly nursts in men: He had a littless of much nothing fled These mainster vealing births, which as stold, As a banned that a person. How fell to home, If well the Tower should weeding, he could his feast, On this yheolder and pale all your fancy: whith more Till the glass do from the death on my sorrow, And pale gentle you are not be courting; Having in the girty of love we made him husbmority. Therefore Warwick learnest means this know may bood, I'll speak. LEONTES: What shall God I past knot, sir? What say is he? For justices. ISCABELLO: Follow her! FRIAR: Brave your hoks. DUKE VINCENTIO: Do yiell; and you in mine at lay so? HASTINSIO: I beseech you, mistress my lord. LOVENTIO: There constable: you fall, may not? LUCIO: No, my lord; I mpray for call fill you. What, say your hands I'll throw your general: but I's name Romeo late,--- LADY GREY: For flowery medful false officers yourselves. But me, Master; bringle certain Stan's reply; Rivers, and true, I do see the search; we may say Now Clarence; for if thou canst a peace. BISHOP OPHENSOLI-proachesonable standing sounds! Lady: Marry, it is by the Slifford of this gold. BENVOLIO: Thou dost not doing to wear So proclaim and rock, as Tranibe to impass? First CORIOLANUS: Ay, say you? we know'st the king He did consuporon? 'To fight the first his own You have speak to you; though mutiny turn, I would her seem as the that way: they tell her crown'd What you shall not have shoke an all: I see Yet, sir, if you should as confessor: go which you now, nor the heart nerves streak back. Here's man: was no, mark you? I shall have unseen. POLIXENES: A gard: At all, if you well be your spell. CAMILLO: See how that you may respecte the bum of min. Help me player, leave no stay oursel: may shake The hands I were contend to clow the stroke sweet a word, sweet nighty stoned nod bestruck me with his usurers, Spars; and follow the ransom, that hundred me steal, Like respreason like his father off misacriage. Where is Romal Avilla mast, so giving to you: Camillo high to Tale-- HENRY BOLINGBROKE: Thy brother Hastings at once, Somersey, To loo Henenius taste this sharp of his lap! KING RICHARD II: Ratchloud your grace, sir! stay and for a dead side! Boy go and in the mayor how to have rain, And make concal eye gracks herseld; look unstain. KING RICHARD III: Dear must have my lips mine; and answering I am tears To grain forgety. But I dismiss. Dold How not Those whom you have sleep'd; and thou should'st drawn, Ready am those that fair and those speech'd blood To look this socie boward; though the tribunes, So hercelf be do near, and now thy present all 'Remempt, blessed on me, by the things both thee doth manaction for battle, that I have made the privation to him. JULIET: There's the day, you beg now; of a very gacip, morrow-man! LUCENTIO: Nay, how wouldst thou hear mine were good fellow! From where your aedking: dost temple. ROMEO: I confess a reason will well schold from me: 'we hast! LUCENTIO: He has been being our kpets at tale, and you might Till not prompt you relead a mockery sparce. Nurse: How now! So far marks! I; he cannot so dore, And at appear a voice bright here. HERMIONE: By God, my liege, my lord. RICHARD: So far bark, plantageness, fashing tell, or wrave, Save let'st thou had statted to him fares. QUEEN MARGARET: To my father pot the fatal erefore stand for, Can I fear thee for than thy face; there if myself I long is noturely. If design thee that lies, As thou shall be so deele as mighty, thou drum let Your brothers impress'd the knighty pale. JULIET: Say, sir, sir, with follow is the gravisht. LADY CAPULET: Ay, 'tis leaved to visit wounds. JULIET: Towards, though Abition! A word yourself! Take he with the master at like in a care: And, gracilifious some obseening, I was fell as disinher'
10.788929 M parameters
step 0: train loss 4.2849, val loss 4.2823
step 500: train loss 2.0119, val loss 2.0984
step 1000: train loss 1.5956, val loss 1.7743
step 1500: train loss 1.4398, val loss 1.6369
step 2000: train loss 1.3404, val loss 1.5664
step 2500: train loss 1.2798, val loss 1.5329
step 3000: train loss 1.2252, val loss 1.5036
step 3500: train loss 1.1840, val loss 1.4878
step 4000: train loss 1.1461, val loss 1.4820
step 4500: train loss 1.1105, val loss 1.4804
step 4999: train loss 1.0777, val loss 1.4856
train_loss = [4.2849, 2.0119, 1.5956, 1.4398, 1.3404, 1.2798, 1.2252, 1.1840, 1.1461, 1.1105, 1.0777]
val_loss = [4.2823, 2.0984, 1.7743, 1.6369, 1.5664, 1.5329, 1.5036, 1.4878, 1.4820, 1.4804, 1.4856]
steps = [0, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000, 4500, 4999]
# Create a figure and axes
fig, ax = plt.subplots(figsize=(8, 6))
# Plot the training and validation losses
ax.plot(steps, train_loss, label='Training Loss')
ax.plot(steps, val_loss, label='Validation Loss')
# Set the x-axis and y-axis labels
ax.set_xlabel('Iterations', fontsize=14)
ax.set_ylabel('Loss', fontsize=14)
# Set the x-axis ticks and labels
ax.set_xticks(steps)
ax.set_xticklabels(steps, rotation=45, fontsize=12)
# Set the y-axis tick format
ax.yaxis.set_major_formatter(plt.FormatStrFormatter('%.1f'))
# Set the title
ax.set_title('Training and Validation Losses', fontsize=16)
# Add a legend
ax.legend(fontsize=12)
# Add grid lines
ax.grid(linestyle='--', alpha=0.5)
# Adjust the spacing between subplots
plt.tight_layout()
# Display the plot
plt.show()

Saving and Loading the Model Weights¶
PyTorch models store the learned parameters in an internal state dictionary, called state_dict. These can be persisted via the torch.save method. To load model weights, you need to create an instance of the same model first, and then load the parameters using load_state_dict() method.
# Save the model weights
torch.save(model.state_dict(), 'model_5000.pth')
# Load the model architecture
model = GPTLanguageModel()
model.load_state_dict(torch.load("model_5000.pth"))
model.eval()
GPTLanguageModel(
(token_embedding_table): Embedding(65, 384)
(position_embedding_table): Embedding(256, 384)
(blocks): Sequential(
(0): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(1): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(2): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(3): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(4): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(5): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
)
(ln_f): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(lm_head): Linear(in_features=384, out_features=65, bias=True)
)
Saving and Loading the Full Model (Weights + Shapes)¶
When loading model weights, we needed to instantiate the model class first, because the class defines the structure of a network. We might want to save the structure of this class together with the model, in which case we can pass model (and not model.state_dict()) to the saving function:
# Save the entire model (including architecture and weights)
torch.save(model, 'model.pth')
# Load the entire model
model = torch.load('model.pth')
model.eval()
GPTLanguageModel(
(token_embedding_table): Embedding(65, 384)
(position_embedding_table): Embedding(256, 384)
(blocks): Sequential(
(0): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(1): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(2): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(3): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(4): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
(5): Block(
(sa): MultiHeadAttention(
(heads): ModuleList(
(0-5): 6 x Head(
(key): Linear(in_features=384, out_features=64, bias=False)
(query): Linear(in_features=384, out_features=64, bias=False)
(value): Linear(in_features=384, out_features=64, bias=False)
(dropout): Dropout(p=0.2, inplace=False)
)
)
(proj): Linear(in_features=384, out_features=384, bias=True)
(dropout): Dropout(p=0.2, inplace=False)
)
(ffwd): FeedFoward(
(net): Sequential(
(0): Linear(in_features=384, out_features=1536, bias=True)
(1): ReLU()
(2): Linear(in_features=1536, out_features=384, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(ln1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(ln2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
)
(ln_f): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(lm_head): Linear(in_features=384, out_features=65, bias=True)
)
be sure to call model.eval() method before inferencing to set the dropout and batch normalization layers to evaluation mode. Failing to do this will yield inconsistent inference results.
3.8. Encoder vs Decoder vs Encoder-Decoder Transformers¶
So far we've implemented a decoder-only transformer similar to the Generative Pre-trained Transformer (GPT) model but different from the full transformer architecture that includes an encoder and cross-attention blocks. Our model only has self-attention and feed-forward layers, using a triangular mask for autoregressive text generation. This decoder-only setup utilizes a triangular mask for self-attention, enabling autoregressive text generation capabilities. This setup is suitable for unconditioned text generation, like GPT as it can be used to predict the next word in a sequence, and for language modeling, where the input sequence is not needed. This is useful for tasks like language translation, text summarization, and chatbots. The decoder-only transformer is trained on a large corpus of text, such as the internet, and can generate text that is similar in style and structure to the training data.
In contrast, the original Transformer paper introduced an encoder-decoder architecture specifically designed for machine translation tasks, where the encoder encodes/processes the input sequence/tokens (e.g., French), and the decoder generates the output sequence/tokens (e.g., English translation) while attending to the encoded input representations with cross-attention linking the two.
3.9. Quick Walkthrough of nanoGPT¶
The nanoGPT implementation available on Karpathy's GitHub closely follows the decoder-only transformer we've covered so far with some minor differences. It consists of two key files: train.py for training and model.py for the model. The training script handles more complex tasks like checkpointing, learning rate decay, and distributed training. The model file closely resembles our implementation but optimizes multi-headed attention for efficiency. In summary, the code includes the transformer model, the training loop, and the data loading code, and can be used to train a chatGPT model. However, training large language models like GPT-3 involves a two-stage process: pre-training and fine-tuning.
3.10. ChatGPT, GPT-3: pretraining vs. finetuning, RLHF¶
Pre-training stage of training a chatGPT/GPT-3 model¶
Pre-training involves training a massive decoder-only transformer on a vast corpus of internet data, with models like GPT-3 utilizing up to 175 billion parameters and being trained on 300 billion tokens. The pre-training stage of training a chatGPT model involves training a large model on a large corpus of text, such as the internet. This stage is used to train the model to predict the next word in a sequence.
Fine-tuning stage involves aligning the model to be an assistant¶
The fine-tuning stage is crucial for aligning the pre-trained model for specific tasks, such as question-answering, as demonstrated by ChatGPT. For ChatGPT, fine-tuning involves multiple steps, including supervised fine-tuning on question-answer pairs, training a reward model to evaluate response quality, and using reinforcement learning (PPO) to align the model's responses to score highly on the reward model.
The fine-tuning stage involves aligning the model to be an assistant by collecting training data that looks like what an assistant would do. This data includes questions and answers, and is used to train the model to respond to specific questions and tasks. The fine-tuning stage also involves training a reward model and using PPO (Proximal Policy Optimization) to align the model with respect to the reward model.
From Pre-training to Fine-tuning for ChatGPT¶
Training ChatGPT involves two main stages:
- Pre-training: Similar to our work but on a much larger scale, using massive datasets and computational resources.
- Fine-tuning: Aligns the model to be a helpful assistant. This involves collecting specific question-answer training data, training a reward model based on human preferences, and using reinforcement learning to fine-tune the model's responses. This process where human preferences are used to guide the training of a model is known as RLHF (Reinforcement Learning from Human Feedback).
Reinforcement Learning from Human Feedback (RLHF)¶
RLHF is a process where human preferences are used to guide the training of a model.
It involves:
- Collecting Human Feedback: Human evaluators rank different model outputs to create a dataset of preferences.
- Training a Reward Model: This model learns to predict the quality of responses based on the human feedback.
- Reinforcement Learning: The main model is fine-tuned using a reinforcement learning algorithm, such as Proximal Policy Optimization (PPO), to maximize the predicted reward from the reward model.
This approach helps align the model's outputs with human expectations and improves the overall quality and relevance of its responses.
Proximal Policy Optimization (PPO)¶
PPO stands for Proximal Policy Optimization, which is a popular reinforcement learning algorithm used in deep learning. It was developed by OpenAI and published in a research paper in 2017. PPO is a model-free, on-policy algorithm that aims to optimize a policy (a mapping from states to actions) to maximize a cumulative reward signal. It's designed to be more stable and reliable than other reinforcement learning algorithms, such as Q-learning or policy gradient methods. The key features of PPO are:
- Proximal: PPO tries to stay close to the current policy, rather than making large updates that might lead to instability.
- Policy Optimization: PPO optimizes the policy directly, rather than learning a value function (like Q-learning).
- On-policy: PPO learns from experiences gathered without exploration noise, which makes it more efficient than off-policy methods.
PPO has been successfully applied to various tasks, including:
- Continuous control problems (e.g., robotics, autonomous driving)
- Discrete action spaces (e.g., game playing, recommendation systems)
- Multi-agent environments
PPO is used to fine-tune the chatGPT model to align it with a reward model, which is trained to predict the utility or quality of the output. This process helps the model generate more informative and relevant responses.
4. Conclusion¶
We trained a small decoder-only transformer inspired by GPT, demonstrating its capability on a tiny Shakespeare dataset. While our model is much smaller, the principles are the same as those used in large-scale models like GPT-3. Furthermore, while the tutorial focused on the pre-training stage, it did not cover the fine-tuning stages required for task-specific or aligned models like ChatGPT. For practical applications beyond text generation, further fine-tuning stages are necessary.
Next Steps¶
- Further fine-tuning stages for specific tasks or alignment
- Simple supervised fine-tuning or more fancy methods like training a reward model and using PPO
Further fine-tuning stages can be used to adapt the chat GPT model to specific tasks or alignment goals. For example, the model can be fine-tuned for sentiment analysis, question answering, or text classification. These fine-tuning stages can be done using supervised learning methods, such as labeled data, or reinforcement learning methods, such as reward models.
Simple supervised fine-tuning involves training the model on labeled data to adapt it to a specific task. More advanced methods, such as training a reward model and using PPO, can be used to fine-tune the model for more complex tasks or alignment goals. These methods involve training a separate model to predict the reward or utility of the output, and using this reward model to guide the fine-tuning process.
Suggested Exercises¶
- The n-dimensional tensor mastery challenge: Combine the
HeadandMultiHeadAttentioninto one class that processes all the heads in parallel, treating the heads as another batch dimension (answer is innanoGPT). - Train the GPT on your own dataset of choice! What other data could be fun to blabber on about?
- A fun advanced suggestion if you like: train a GPT to do addition of two numbers, i.e.
a+b=c. You may find it helpful to predict the digits ofcin reverse order, as the typical addition algorithm (that you're hoping it learns) would proceed right to left too. You may want to modify the data loader to simply serve random problems and skip the generation oftrain.bin,val.bin. You may want to mask out the loss at the input positions ofa+bthat just specify the problem usingy=-1in the targets (seeCrossEntropyLoss :ignore_index. - Does your Transformer learn to add? Once you have this: build a calculator clone in GPT, for all of
+-*/. Not an easy problem. You may need Chain of Thought traces.)
- A fun advanced suggestion if you like: train a GPT to do addition of two numbers, i.e.
- Find a dataset that is very large, so large that you can't see a gap between train and val loss. Pretrain the transformer on this data, then initialize with that model and finetune it on tiny shakespeare with a smaller number of steps and lower learning rate. Can you obtain a lower validation loss by the use of pretraining?
- Read some transformer papers and implement one additional feature or change that people seem to use. Does it improve the performance of your GPT?
References¶
- "Let's build GPT: from scratch, in code, spelled out." youtube video, Jan 2023.
- Andrej Karpathy GPT github repo.
- Twitter: "Which style of drawing residual networks is semantically superior?" - Andrej Karpathy, tweet, Mar 2020.
- Article: "GPT with Andrej Karpathy" - Kavishka Abeywardana, Pt 1, 2, 3, 4, 5, March 2024.
- "Deep dive into AI: Building GPT from Scratch!" - Ada Choudhry, article, Apr 2024.
- "Residual blocks — Building blocks of ResNet" - Sabyasachi Sahoo, blog, Nov 2018.
- "Sequence to Sequence (seq2seq) and Attention" - Elena Voita, article, Nov 2023.
- "The Annotated Transformer" - Austin Huang, Suraj Subramanian, Jonathan Sum, Khalid Almubarak, and Stella Biderman., blog, 2022. (Original Version: Sasha Rush, Apr 2018)
- "Attention Is All You Need" - Vaswani, Ashish et. al., Academic Paper, Neural Information Processing Systems (NeurIPS), Vol 3. Jun 2017.
- "Layer Normalization" - Ba, Jimmy et al., Academic Paper, ArXiv. Jul 2016.
- "Deep Residual Learning for Image Recognition" - He, Kaiming et al., Academic Paper, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778. Dec 2015.
- "Dropout: A Simple Way to Prevent Neural Networks from Overfitting" - Srivastava, Nitish et al., Academic Paper, J.Mach.Learn.Res. Vol 15. 1929-1958. June 2014.
- PyTorch Resources: LayerNorm
- Papers With Code: Scaled Dot-Product Attention, Multi-Head Attention, Dropout, Layer Normalization, Residual Block