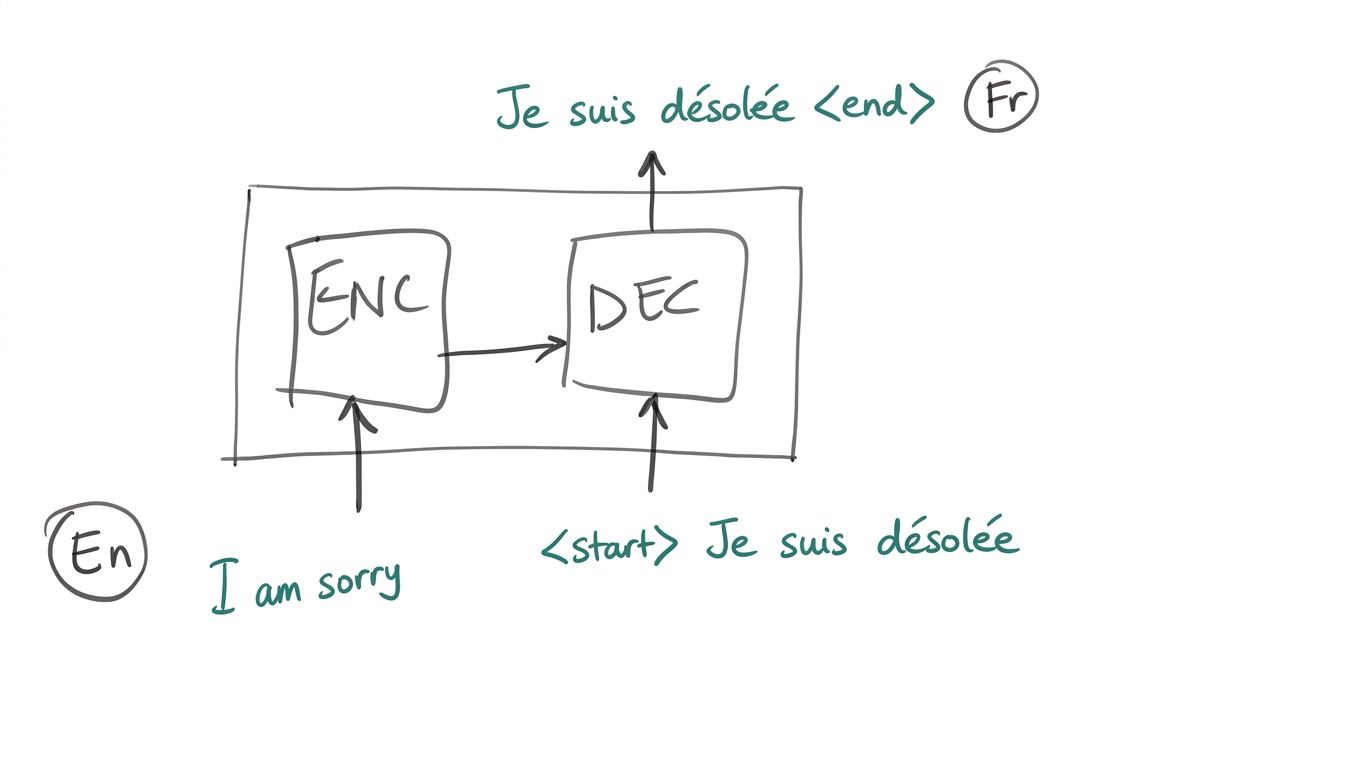
Transformers
- Transformers are a sequence-to-sequence model: given an input sequence, produce an output sequence.
- Architecture: an Encoder processes the input; a Decoder generates the output autoregressively.
- Autoregressive: the decoder generates one token at a time, conditioning on all previously generated tokens.
Table of Contents
- Input Text Sequence Representation
- Encoders
- From MLP to Attention
- Self-Attention & Multi-Head Attention
- Decoders
- Masked Attention
- Encoder-Decoder Cross Attention
Appendix
Input Text Sequence Representation
Tokenization
Two approaches to representing input text:
1. One-hot encoding
- No semantic similarity or meaning of words encoded.
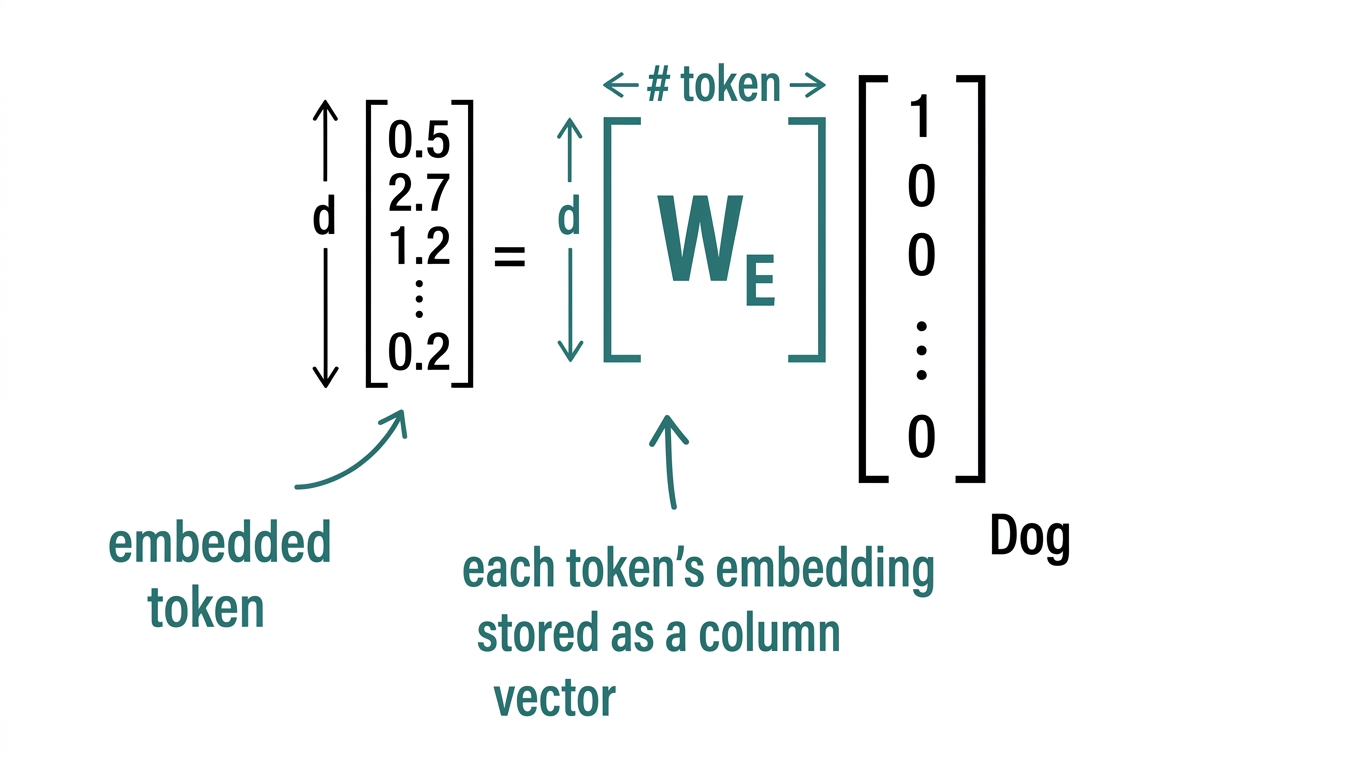
2. Token embedding
- Encodes semantic similarity between words.
- Embedding matrix is learned (Lookup Table).
- Each token embedding is stored as a column vector.
Why We Need Context
- Many words have different meanings in different contexts:
- “I bought an apple & an orange”
- “I bought an apple watch”
- We need to rely on context to resolve the ambiguity.
Encoders
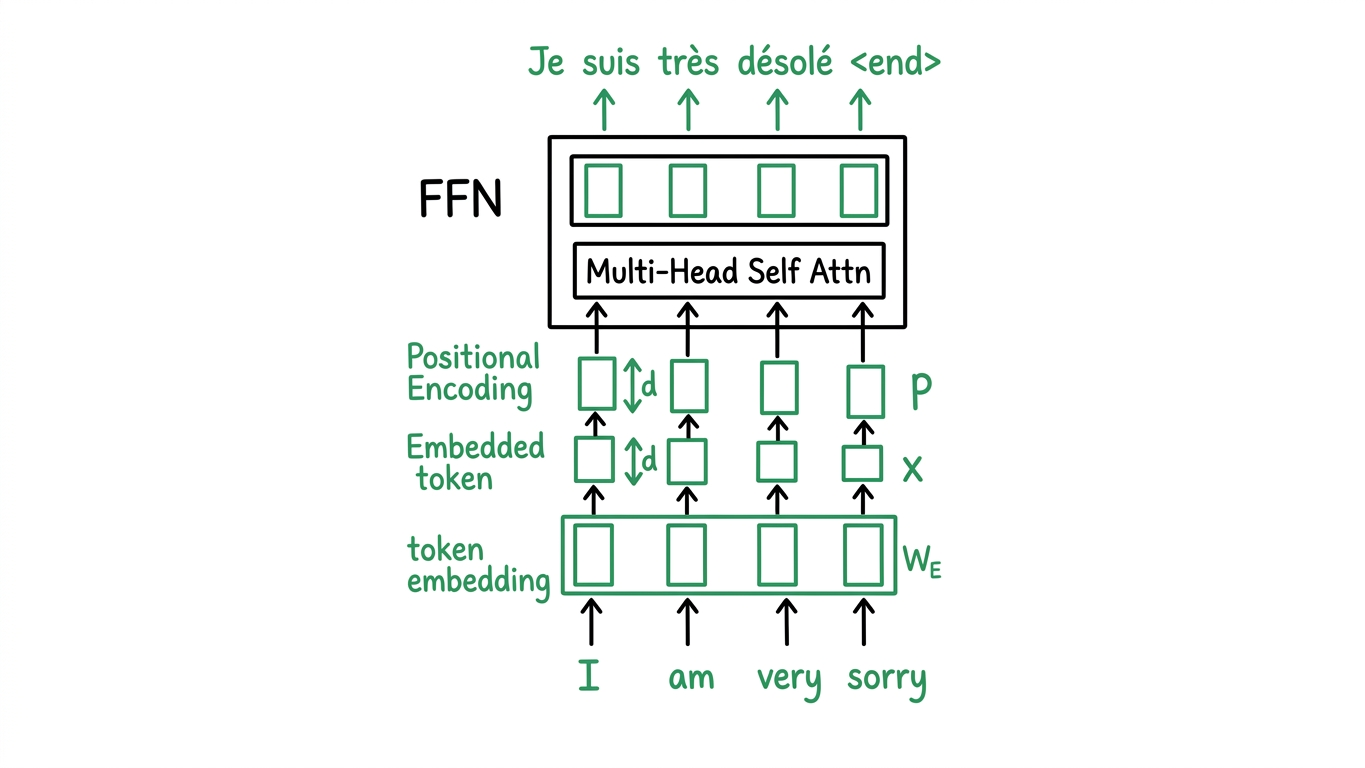
The encoder pipeline:
\[\text{Input} \to \text{token} + \text{POS embed} \to \text{Norm} \to \text{MHA(self)} \to \text{Add} \to \text{Norm} \to \text{FFN} \to \text{Add} \to \text{Output}\]- Input tokens are embedded using $W_E$ and combined with positional encodings to produce the input matrix $X$.
- The architecture stacks: Multi-Head Self-Attention + residual, then FeedForward Network + residual.
From MLP to Attention
MLP only
- MLP stands for Multilayer Perceptron
- No contextual information; each token is processed independently.
Concatenation of nearby token embeddings before MLP
- Need a sufficiently large window to cover the entire input sequence.
- Cannot handle variable sequence lengths.
- Requires many model parameters.
Attention
- Use token similarity to determine the relevance of each token to every other token by performing a dot product.
- Allows the model to dynamically weight which parts of the input are relevant for each position.
Self-Attention & Multi-Head Attention
Self-Attention
\[Q = XW_Q, \quad K = XW_K, \quad V = XW_V\] \[\text{head}_i = \text{Softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}\right)V = \text{Attention}(Q, K, V)\]Multi-Head Attention (MHA)
\[\text{MHA}(X) = \text{multi-head}(Q, K, V) = \text{Concat}(h_1, h_2, \ldots, h_H)\, W_O = Z\] \[\begin{aligned} \text{where} \\ h_i &\equiv i\text{-th attention head} \\ W_O &\equiv \text{output projection matrix} \\ Z &\equiv \text{final output} \end{aligned}\]Decoders
The decoder pipeline:
\[\text{Masked MHA} \to \text{Cross-Attn} \to \text{FFN} \to \text{Linear} \to \text{Softmax} \to \text{Output}\]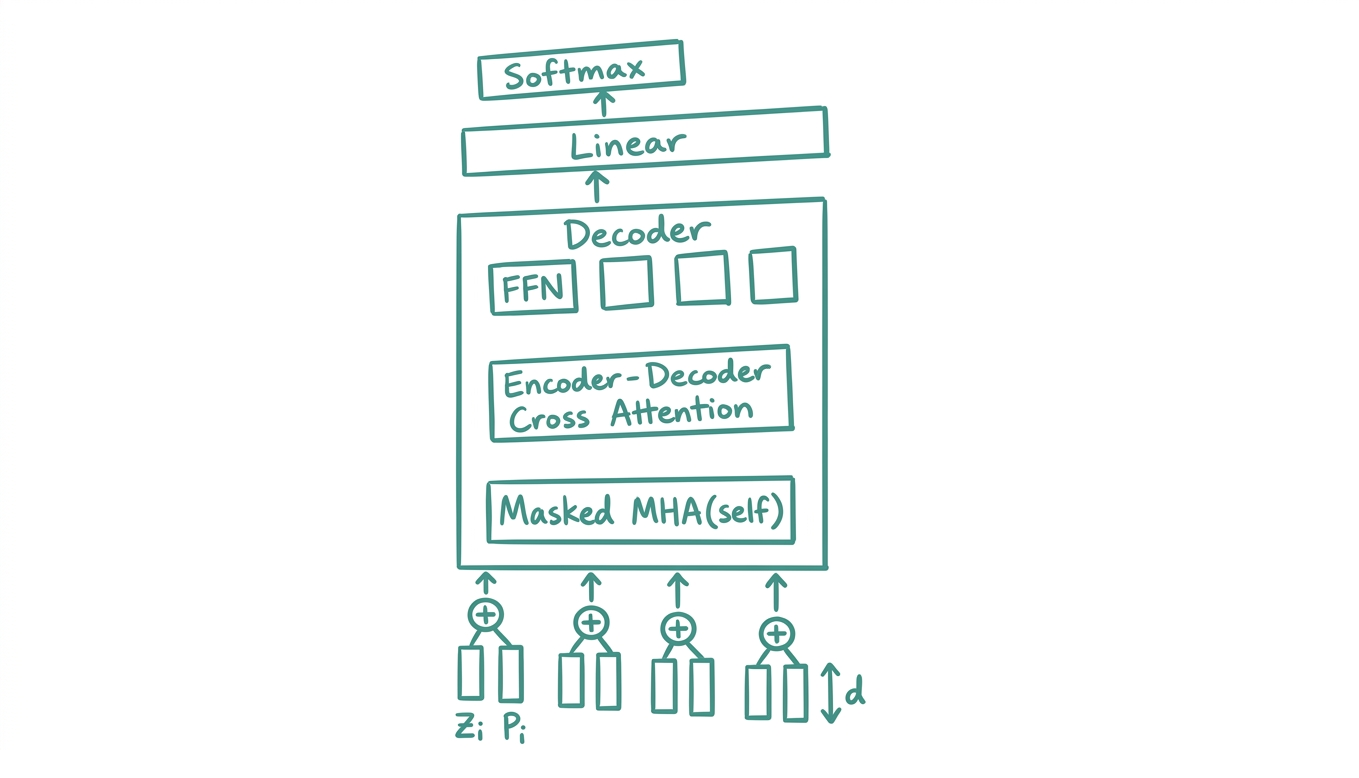
The decoder takes as input the previously generated tokens $(z_i)$ along with their positional encodings $(p_i)$, and at each step attends both to itself (masked) and to the encoder output (cross attention).
Masked Attention
In the decoder, we use masked (causal) self-attention to prevent the decoder from attending to future tokens:
\[\text{Masked Attn}(Q, K, V) = \text{Softmax}\!\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V\] \[\begin{aligned} \text{where} \\ M &\equiv \text{lookahead mask} \end{aligned}\] \[M = \begin{bmatrix} 0 & -\infty & -\infty & -\infty \\ 0 & 0 & -\infty & -\infty \\ 0 & 0 & 0 & -\infty \\ 0 & 0 & 0 & 0 \end{bmatrix}\]Adding $-\infty$ to future positions drives their softmax weights to zero, ensuring position $i$ can only attend to positions $\leq i$.
Encoder-Decoder Cross Attention
The decoder queries the encoder output $E$ (encoder output) to incorporate source context:
\[\begin{aligned} Y' &= Y + \text{Masked MHA}(\text{Norm}(Y)) \\[6pt] Q &= Y' W_Q^{\text{dec}} \\ K^{\text{enc}} &= E W_K^{\text{enc}} \\ V^{\text{enc}} &= E W_V^{\text{enc}} \end{aligned}\] \[\begin{aligned} \text{where} \\ E &\equiv \text{encoder output} \end{aligned}\] \[\text{Cross Attn}(Y', E) = \text{Softmax}\!\left(\frac{Q K_{\text{enc}}^T}{\sqrt{d_k}}\right)V^{\text{enc}}\]Then the rest of the decoder:
\[\begin{aligned} Y'' &= Y' + \text{Cross Attn}(\text{Norm}(Y'),\ E) \\ Y^O &= Y'' + \text{FFN}(\text{Norm}(Y'')) \\ D &= Y^O \\ \text{logits} &= DW^{\text{out}} + b \\ P(y_t) &= \text{Softmax}(\text{logits}_t) \end{aligned}\] \[\begin{aligned} \text{where} \\ D &\equiv \text{decoder output} \\ W^{\text{out}} &\equiv \text{output projection to vocabulary} \\ P(y_t) &\equiv \text{probability distribution over next token} \end{aligned}\]Citation
If you found this blog post helpful, please consider citing it:
@article{obasi2026transformers,
title = "Transformers",
author = "Obasi, Chizoba",
journal = "chizkidd.github.io",
year = "2026",
month = "Apr",
url = "https://chizkidd.github.io/2026/04/05/transformers/"
}