SAM 2 Explained: Meta's Promptable Visual Segmentation Model
- Meta’s unified model for promptable image and video segmentation.
- A foundation model for solving promptable visual segmentation in images & videos.
- Built a data engine to collect the largest video segmentation dataset to date.
- Model: Simple transformer architecture with streaming memory for real-time video processing.
- Trained on a wide range of tasks: video segmentation and image segmentation.
- The paper can be found here.
Table of Contents
- 1. Introduction
- 2. Related Work
- 3. Task: Promptable Visual Segmentation (PVS)
- 4. Model
- 5. Data
- 6. Zero-Shot Experiments
- 7. Comparison to SOTA in Semi-Supervised VOS
- 8. Conclusion
- 9. Discussion
Appendix
1. Introduction
Why video and not image?
- Image is only a static snapshot of the real world; lacks motion information (temporal).
- Video captures temporal information.
- Many vital applications (robotics, AR/VR, autonomous vehicles) require temporal localization beyond image-level segmentation.
- A universal visual segmentation system should be applicable to both images & videos.
- Video segmentation aims to determine the spatio-temporal extent of entities, which presents unique challenges beyond those in images.
- Significant changes in appearance encountered by entities & lower quality nature of videos than images present challenges for video segmentation.
- SAM successfully solves image segmentation, but existing video segmentation models & datasets fall short in providing a comparable capability to “segment anything in videos.”
- SAM 2: A unified model for video & image segmentation.
- Promptable Visual Segmentation (PVS): Task that generalizes image segmentation to the video domain.
- A data engine that generates training data via an in-the-loop model with annotators and produces the Segment Anything Video (SA-V) dataset.
2. Related Work
- Video Object Segmentation (VOS)
- Video augmentation datasets
- Interactive Video Object Segmentation (iVOS)
- Image Segmentation task, model and dataset
- Research Paper: Segment Anything (SA)
We aim to build a foundation model for segmentation by introducing three interconnected components: a promptable segmentation task, a segmentation model (SAM) that powers data annotation and enables zero-shot transfer to a range of tasks via prompt engineering, and a data engine for collecting SA-1B, our dataset of over 1 billion masks.
3. Task: Promptable Visual Segmentation (PVS)
\[\text{PVS} \longrightarrow \text{SAM 2} \longrightarrow \text{SA-V dataset}\]- PVS task allows providing prompts to the model on any frame of a video.
- The interactive segmentation with SAM2 involves the steps below:
- SAM 2 is prompted on a single frame and responds instantly with a valid segmentation mask of the target object on this frame.
- SAM 2 then propagates the target object’s segment to multiple frames to form a masklet.
- Multiple initial prompts are received and propagated by the model to obtain the masklet of the object across the entire video, which leads to localization of the segmentation mask of the target on every single video frame.
- Additional prompts on any frame can be added to SAM 2 for segmentation mask refinement.
- SAM 2 is applied as a data collection tool to the PVS task for building the SA-V dataset.
- Model evaluation is done via simulation of interactive video segmentation scenarios across multiple frames in the conventional first-frame, limited, semi-supervised VOS setting, and for image segmentation on the SA benchmarks.
4. Model
SAM 2 is a generalization of SAM to the video (& image) domain. Essentially, it employs taking point, box & mask prompts on individual frames to define the spatial extent of the object to be segmented spatio-temporally.
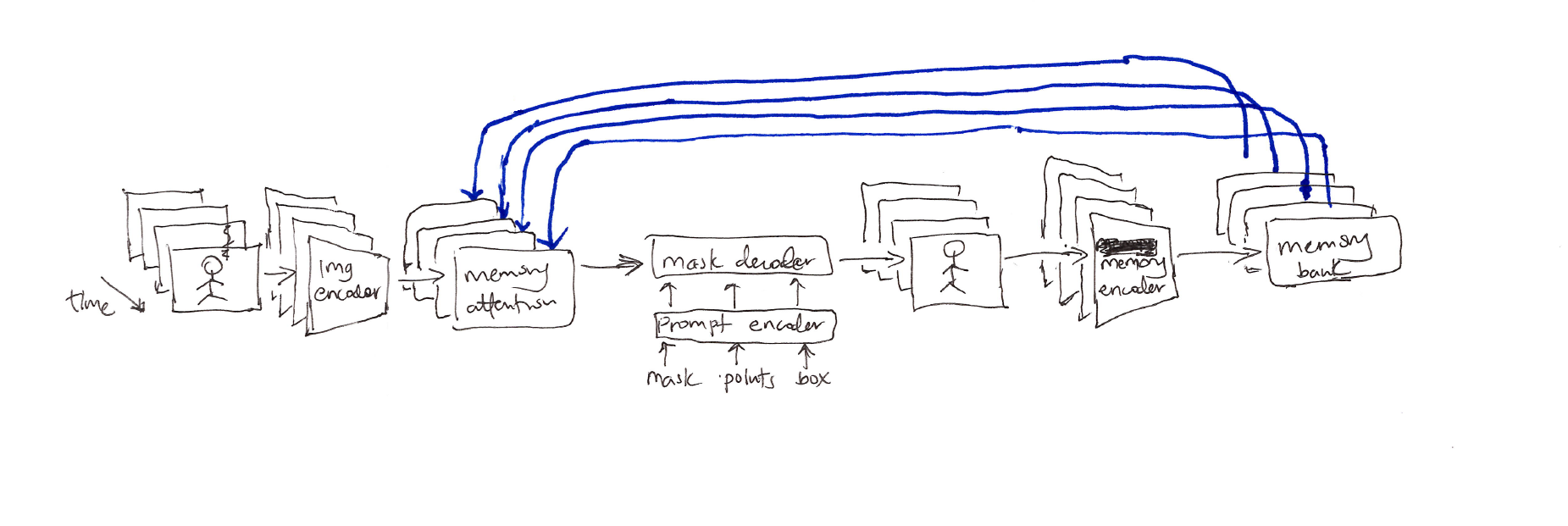
Figure 1: The SAM 2 architecture. For a given frame, the segmentation prediction is conditioned on the current prompt and/or on previously observed memories. Video frames are processed in a streaming fashion by the image encoder, cross-attended to memories of the target object from previous frames stored in the memory bank, and decoded via the mask decoder (optionally prompted by the prompt encoder) to predict the segmentation mask for that frame. Finally, a memory encoder transforms the prediction and image encoder embeddings for use in future frames.
Components:
- Image encoder: For real-time processing of arbitrarily long videos via a streaming, hierarchical approach.
- Memory attention: Condition the current frame features on the past frames features and predictions or any new prompts.
- Prompt encoder & mask decoder: Encode and send the input prompts to the mask decoder to predict the segmentation mask for the current frame.
- Memory encoder: Generates a memory by downsampling, element-wise summation and light-weight convolution of the output mask which fuses the information.
- Memory bank: Stores spatial memory information (from prompts) about past predictions for the target object in the video, and high-level semantic information of the object to segment based on each frame’s mask decoder output tokens.
Training:
The model is trained jointly on image and video data via interactive prompting simulation of the model, sequential sampling of 8 frames and random selection of 2 frames to prompt, with the goal of sequential and interactive prediction of the gound-truth masklet.
5. Data
The data engine was built, by an interactive in-the-loop model setup with human annotators, to collect a large and diverse video segmentation dataset to develop the “segemnt anything” capability in video. The data engine underwent 3 phases, each based on the level of model assistance provided to annotators.
5.1 Data Engine
- Phase 1: SAM per frame
- Phase 2: SAM + SAM 2
- Phase 3: SAM 2
- Quality verification including a separate set of QA annotators for the masklets (satisfactory or unsatisfactory)
- Auto masklet generation enables the “anything capability” of the model by ensuring annotation diversity.
- Analysis 1: Comparison in each data engine phase through a controlled experiment of the average annotation time per frame, the average percentage of manually edited frames per masklet, and the average number of clicks per clicked frame. For QA, the defined metric is called Phase 1 Mask Alignment Score, the percentage of masks whose IoU compared to the corresponding masks in Phase 1 (highest quality manual annotations) exceeds 0.75.
- Analysis 2: Performance comparison of SAM 2 trained on the available data at the end of each phase keeping the number of iterations fixed, therefore measuring solely the impact of the additional data. Evaluation is done on the SA-V val dataset and 9 zero-shot benchmarks using the standard $J\&F$ accuracy metric.
Phase 3 is 8.4× faster than Phase 1, has the lowest edited frame percentage and clicks per frame, and results in better alignment.
Consistent segmentation accuracy improvement from iteratively adding data from each data engine phase (1, 2 & 3) for both SA-V val set and 9 zero-shot benchmarks is observed.
5.2 SA-V Dataset
- Videos (50.9K total, 54% indoor + 46% outdoor scenes, average duration of 14 secs)
- Masklets (190.9K manual + 451.7K automatic, 642.6K total)
- SA-V training, validation (293 masklets & 155 videos) & test splits (278 masklets & 150 videos)
- Internal dataset (62.9K videos & 69.6K masklets annotated in Phase 2 & 3 for training; 96 videos & 189 masklets annotated using Phase 1 for testing)
6. Zero-Shot Experiments
- Compare SAM 2 with previous work on zero-shot video & image tasks using the $J\&F$ accuracy metric.
6.1 Promptable Video Segmentation (PVS)
- First evaluate PVS, which involves simulating an interactive setting that is akin to the user experience. Both evaluation settings below are done on 9 densely annotated zero-shot video datasets using $N_{click} = 3$ clicks per frame and are compared to 2 strong baselines based on 2 SOTA VOS models (XMem++ & Cutie)
- Offline evaluation: multiple passes made through a video for frame selection via the largest model error.
- Online evaluation: single forward pass for video frames’ annotation.
6.2 Semi-Supervised Video Object Segmentation
- Evaluate the semi-supervised VOS setting with click, box or mask prompts only on the 1st frame of the video.
- For click prompts, try either 1, 3, or 5 clicks on the 1st video frame (mIoU).
- Comparison is done via $J\&F$ accuracy between SAM + XMem++, SAM + Cutie and SAM 2.
6.3 Image Segmentation
- Evaluate SAM 2 on the Segment Anything task across 37 zero-shot datasets using 1-click and 5-click mIoUs.
7. Comparison to SOTA in Semi-Supervised VOS
- Evaluate 2 versions of SAM 2 with varying image encoder sizes with different speed-vs-accuracy tradeoffs.
- Comparison with existing SOTA models/methods via accuracy ($J\&F, G$) using standard protocols.
- Evaluate existing work on the SA-V val & test sets which measure performance for open-world segments of “any” object class via $J\&F$ accuracy metric.
SAM 2 performs well in accuracy for video segmentation based on first-frame ground-truth mask prompts.
SAM 2 performs significantly better on SA-V val/test.
8. Conclusion
Present a natural extension of Segment Anything into the video domain, based on 3 key aspects:
- Extending the promptable segmentation task to video.
- Equipping the SAM architecture to use memory when applied to video.
- The diverse SA-V dataset for training & benchmarking video segmentation.
The authors believed SAM 2 marked a significant advancement in visual perception, positioning their contributions as milestones that will propel further research & applications.
9. Discussion
When I first read about SAM 2’s memory bank component, my immediate thought was: this feels familiar. Not because it copies prior work, but because it sits at an intersection I’ve been circling for a while: how do neural systems remember what matters, without remembering everything?
SAM 2 maintains object identity across video frames by storing two kinds of information in its memory bank:
- Spatial feature maps from up to
Nrecent frames andMprompted frames (stored in FIFO queues) - Object pointers: lightweight semantic vectors derived from the mask decoder’s output tokens
Memory attention then cross-attends over both when predicting the current frame. This design elegantly sidesteps the sequential bottleneck that plagued RNNs. Instead of compressing history into a single fixed-length hidden state, SAM 2 gives the model direct, position-invariant access to past representations. The “distance” between frame 1 and frame 200 is functionally the same as between frame 199 and 200. In that sense, attention acts as a temporal superhighway.
Key distinction: RNNs encode history into a single vector (making long-range dependencies hard). SAM 2’s attention mechanism bypasses that bottleneck entirely, so distance becomes irrelevant. But attention solves the access problem, not the retention problem.
And that’s where the FIFO design matters. The paper explicitly states that the memory bank evicts the oldest frame once the queue is full, regardless of semantic importance.1 This validates a subtle but critical observation: SAM 2’s forgetting mechanism is a fixed heuristic, not a learned one. The model doesn’t decide what to remember based on future tracking utility; it drops frames based on arrival time.
This creates a tangible trade-off between memory availability and diagnostic utility. Consider an object that:
- Undergoes dramatic lighting change
- Is occluded for dozens of frames
- Reappears with significant appearance deformation
The frames that best capture its initial identity might be evicted long before it reappears. Meanwhile, newer frames with degraded or ambiguous representations linger in the queue simply because they arrived later. The “object pointers” partially mitigate this by storing lightweight semantic summaries, but they’re still bound by the same FIFO eviction policy. If the pointer for frame t is overwritten, the model loses not just the spatial map but also its high-level anchor.
time-based eviction] --> B[Eviction Policy
fixed heuristic] B --> C[Memory Attention
position-invariant access] C --> D{Tracking Outcome} D -->|Object reappears
with useful memory| E[✓ Success] D -->|Key frame evicted
or pointer overwritten| F[✗ Failure] style A fill:#e3f2fd style B fill:#fff3e0 style C fill:#e8f5e9 style E fill:#c8e6c9,stroke:#2e7d32 style F fill:#ffcdd2,stroke:#c62828
Figure 2: The memory bank’s fixed eviction policy (FIFO) interacts with attention’s position-invariant access. When evicted frames contain critical identity information, tracking fails; even if attention could theoretically retrieve them.
The paper’s handling of temporal position encoding reinforces this pragmatic trade-off. Temporal embeddings are injected into the N recent frames to capture short-term motion, but deliberately omitted from prompted frames due to sparse training signals and inference generalization concerns. This is a sound engineering decision, but it reveals a boundary: SAM 2 optimizes for stable, short-to-medium horizon tracking, not open-ended temporal reasoning.
Where This Fits in the Broader Literature
SAM 2’s memory bank isn’t operating in a vacuum. It shares conceptual DNA with several prior lines of work:
- Neural Turing Machines introduced differentiable external memory with read/write heads, allowing networks to learn what to store and where to retrieve from 2. SAM 2’s memory attention is a specialized, non-differentiable cousin: it retrieves, but doesn’t learn the eviction policy.
- RETRO demonstrated that retrieval-augmented transformers can scale knowledge without scaling parameters, by querying a frozen corpus at inference 3. SAM 2 does something analogous for video: query a frozen buffer of past frames. The open question is whether that buffer should be learned, not fixed.
- TimeSformer showed that spatiotemporal attention alone can handle video understanding without recurrent components 4. SAM 2 extends this by adding explicit memory, and also inherits TimeSformer’s assumption that all frames are equally worth attending to.
What SAM 2 adds is a practical instantiation of these ideas for promptable segmentation. It’s not trying to solve general memory-augmented reasoning; it’s solving “keep this object tracked, please.” That focus is its strength; and its limitation.
About memory design, I’d say: “FIFO is computationally cheap and training-stable, which makes sense for a production model. But from a research standpoint, it hardcodes a failure mode: important frames get evicted by time, not relevance. A differentiable memory controller or retrieval-augmented eviction policy could close that gap.”
Why This Matters
There’s a tendency in ML to treat architectural choices as purely engineering decisions. But memory management isn’t just about compute budgets, it’s also about what the model values. When SAM 2 drops a frame because it’s old, not because it’s uninformative, it’s making a silent claim: recency matters more than relevance.
That claim works well for many tracking scenarios. But it breaks down when objects reappear after long occlusions, or when appearance changes dramatically. In those cases, the model isn’t failing because attention is weak; it’s failing because the right information was never kept around to attend to.
This isn’t unique to SAM 2. It’s a fundamental tension in any system that must balance finite memory against infinite context. But because SAM 2 is a foundation model positioned for broad adoption, its design choices will influence how thousands of downstream applications handle temporal reasoning. Getting the memory story right matters.
So where does this leave us? SAM 2 is undoubtedly a milestone in promptable video segmentation. But its memory bank inadvertently frames a deeper research problem: attention removes the barrier of temporal distance, but leaves the bottleneck of memory management wide open.
Open Questions I’d Want to Explore
- Learnable eviction: Could we replace FIFO with a lightweight, content-aware, learnable memory eviction mechanistic network that predicts which frames to retain based on tracking confidence, appearance stability, or semantic salience? Would SAM 2 maintain robust identity over arbitrarily long horizons? What’s the compute trade-off from an engineering system to a long-context reasoning model?
- Pointer robustness: The object pointers are a clever compression trick, but they’re still overwritten by FIFO. Could we decouple pointer retention from spatial memory eviction?
- Cross-video retrieval: RETRO retrieves from a corpus of documents; could SAM 2 retrieve from a corpus of past videos to bootstrap tracking of familiar objects?
- Failure diagnostics: Can we design a probe that predicts when SAM 2 is likely to lose an object, based on memory bank state? That would be valuable for safety-critical applications.
I don’t have answers to these yet. But they feel like the right questions to ask if we want video models that don’t just see, but remember. SAM 2 shows we’ve mastered access to the past. The next step is mastering retention of what matters.
Citation
If you found this blog post helpful, please consider citing it:
@article{obasi2026sam2,
title = "SAM 2: Segment Anything in Images & Videos",
author = "Obasi, Chizoba",
journal = "chizkidd.github.io",
year = "2026",
month = "Apr",
url = "https://chizkidd.github.io/2026/04/17/sam2/"
}
References
-
Ravi N, Gabeur V, Hu Y-T, et al. SAM 2: Segment Anything in Images and Videos. arXiv. 2024. ↩
-
Graves A, Wayne G, Danihelka I. Neural Turing Machines. arXiv. 2014. ↩
-
Borgeaud S, Mensch A, Hoffmann J, et al. Improving Language Models by Retrieving from Trillions of Tokens. arXiv. 2022. ↩
-
Bertasius G, Wang H, Torresani L. Is Space-Time Attention All You Need for Video Understanding?. arXiv. 2021. ↩