When Your Voice Assistant Can't Hear Tones: Evaluating ASR Bias in Igbo
I grew up in an Igbo household in Northern Nigeria, that code-switched between English, Igbo, and Hausa almost unconsciously. Like many bilingual Nigerians, I’ve watched voice assistants and ASR systems get better and better at English while struggling with our languages. When Meta released omniASR claiming support for over 1,600 languages including Igbo, I was curious. Does “supported” mean it actually works?
Turns out, the answer is more complicated than I expected.
The Problem: What Does “Language Support” Really Mean?
Here’s the thing about Igbo: tone changes word meaning. The difference between “akwa” (crying), “akwà” (cloth), “àkwà” (egg), and “ákwá” (bridge) isn’t just decorative accent marks. These are completely different words that happen to have the same consonants and vowels. The tone is the difference.
So when I saw that omniASR listed Igbo among its supported languages, I wanted to know: does it actually preserve these tonal distinctions? Or does “support” just mean “we trained on some Igbo data and hope for the best”?
The Experiment: 21 Audio Samples
I designed a simple test. Using my iPhone Voice Memos app, I recorded 21 short audio clips in different categories:
Tonal minimal pairs: I said “akwa, akwa, akwa” three times with no tone, then “akwà, akwà, akwà” three times with low tone, then “àkwà, àkwà, àkwà” with low-low tone, and finally “ákwá, ákwá, ákwá” with high-high tone. Four distinct words, each repeated three times.
Code-switching: Phrases like “The ụlọ is beautiful” where I mix English and Igbo naturally, the way we actually speak.
Place names and cultural terms: Nigerian cities, Igbo food words, proverbs. The stuff that’s probably not in training data.
The smoking gun test: I spoke a sentence with deliberately flat intonation, no tonal variation at all. If the model is actually listening to tone in the audio, it shouldn’t add tone marks to monotone speech.
Then I ran everything through omniASR and compared what I actually said to what it transcribed.
The Results: 75% Tone Loss
The numbers were worse than I expected.
For the tonal sample after bootstrapping, the model dropped 75.5% of the tone marks. Not just a few mistakes here and there. Three out of every four tone marks, gone.
When I said the four different “akwa” words, the model output was: “akua akua akua akua akwa akwa akwa akua akwa ọkua ọkua ọkua”. Random variations. The semantic distinctions completely lost.
But here’s what really convinced me the model isn’t actually listening to tones: the monotone test. I spoke “O na-eri oji n’ututu” (He eats kolanut in the morning) with flat intonation, like a robot. The model transcribed it as “ọne rị ọjí nụ tútú” and added tone marks that I never spoke.
If the model were using acoustic information to place diacritics, it shouldn’t be adding tones to flat speech. This suggests it’s doing something else: probably using statistical patterns from training data to guess where diacritics should go, rather than actually hearing them.
File 09: Spoke “O na-eri oji n’ututu” with FLAT intonation
Expected: 0 diacritics (no tonal variation in audio)
Result: Model added 7 tone marks that weren’t spoken
This is evidence of orthographic bias, not acoustic perception.
What the Data Shows
I created three visualizations to make the patterns clear.
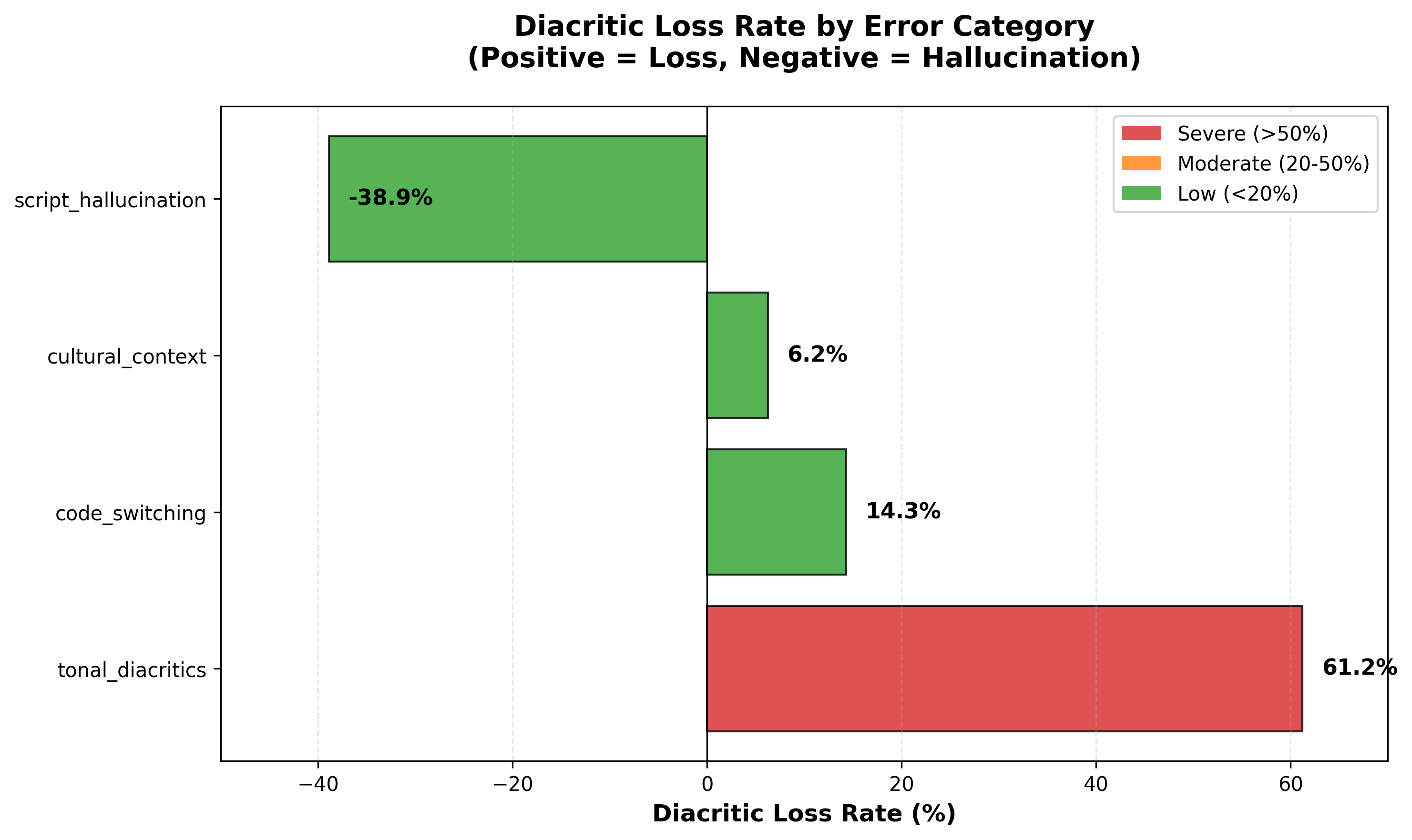
Figure 1 shows diacritic loss by category. The tonal category (in red) jumps out immediately at 61.2% raw count loss. For comparison, the domain-specific category had only 6.3% loss. But look at the cross-lingual interference category: it’s at -38.9%, which means the model was adding diacritics that don’t exist. It’s not just dropping tones, it’s hallucinating them in the wrong places.
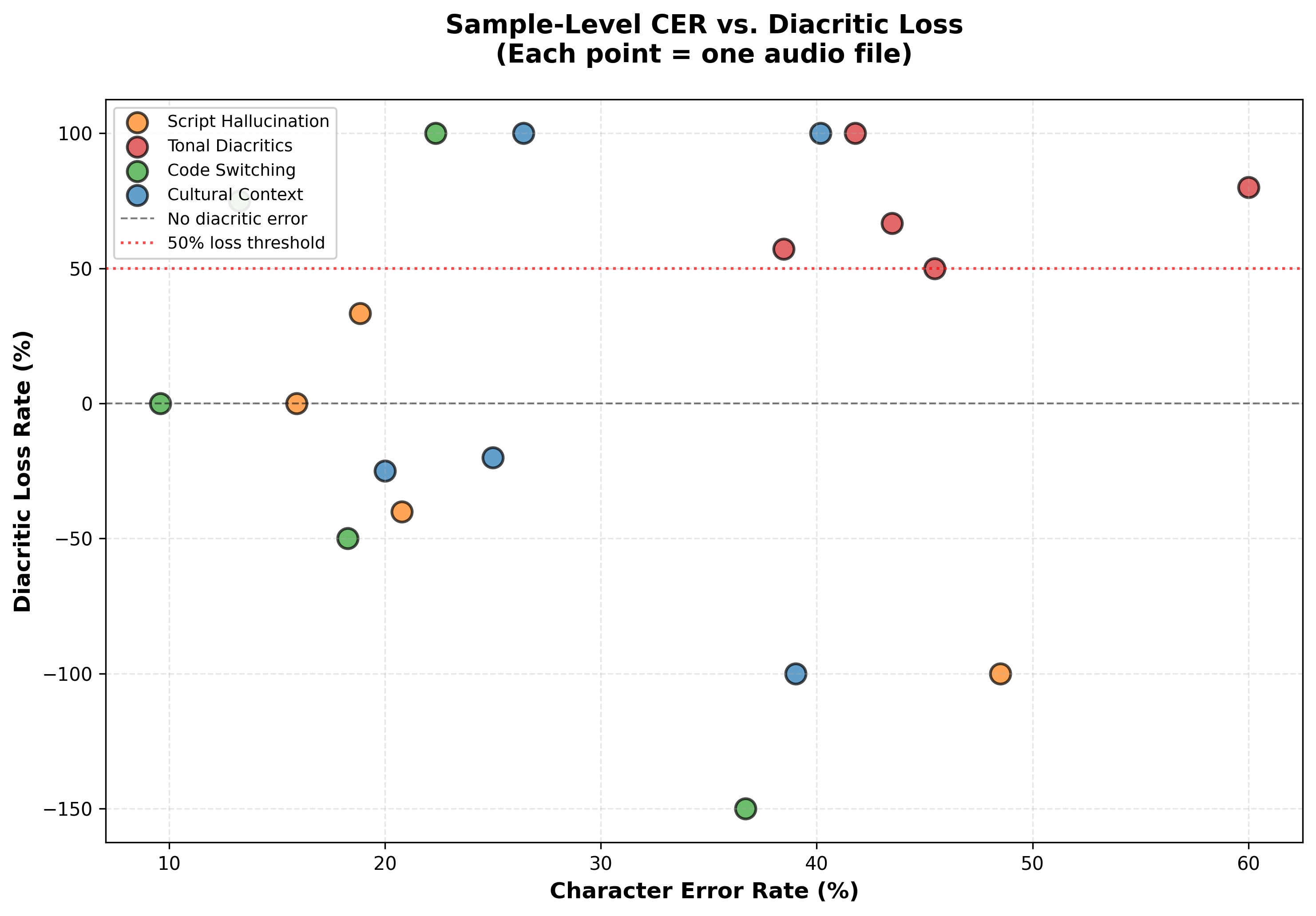
Figure 2 plots character error rate against diacritic loss for each sample. What’s interesting here is that the tonal samples (red dots) show high diacritic loss even when the overall character error rate is moderate (20-40%). This means tone errors aren’t just a consequence of the model doing poorly in general. The model can get most of the characters right while still completely failing on tones specifically.
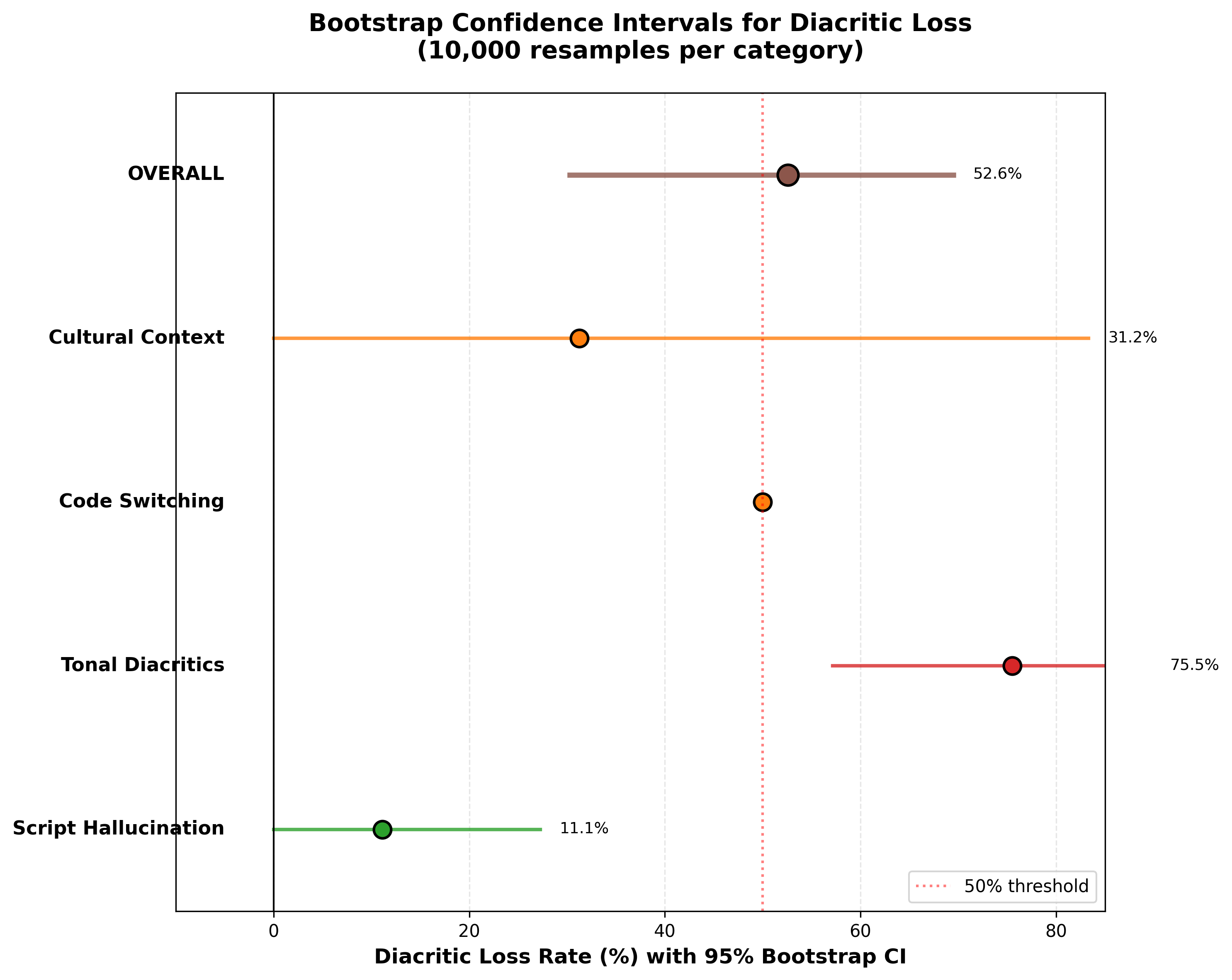
Figure 3 shows the bootstrap confidence intervals. Even with only 21 samples, the error bars don’t overlap between categories. The tonal category’s worst-case lower bound is 57.1%, which is still terrible. This confirms that what I’m seeing isn’t just noise from a small sample size.
The Statistical Story
I’m not a statistician, but I know enough to be careful with small sample sizes. Twenty-one samples isn’t huge. So I used bootstrap resampling (basically, randomly resampling my data 10,000 times to get confidence intervals) to make sure these effects weren’t just random noise.
Even under the most conservative estimate (the lower bound of the 95% confidence interval), tonal diacritic loss was still 57.1%. The worst-case scenario is still terrible.
I also created a custom metric called Diacritic Error Rate (DER) because standard Character Error Rate treats tone marks the same as spacing errors. DER specifically tracks dropped tone marks versus hallucinated tone marks. Turns out the model isn’t just dropping tones. It’s also adding tones that don’t exist, which is a whole different kind of problem.
The Categories
Breaking down the errors helped me understand what’s going wrong:
Cross-lingual interference: When I spoke phrases with no tone marks at all (like names), the model added incorrect diacritics 38.9% of the time. It’s probably applying orthographic patterns from other languages.
Code-switching boundary effects: The English portions of code-switched sentences were transcribed perfectly. The Igbo portions immediately adjacent to English lost their tones. Something about language boundaries is disrupting processing.
Domain coverage: Culturally specific terms (place names, food words) had the best diacritic preservation at only 6.3% loss, but terrible overall accuracy. The model knows the orthography but doesn’t know the words.
Tonal collapse: 75.5% loss. This is the big one.
Why This Matters
I keep coming back to the monotone hallucination test. If I were building a voice assistant for Igbo speakers and it’s adding tones I didn’t speak, that’s not just an accuracy problem. It’s an epistemological problem. The system is presenting confident outputs that have no acoustic basis.
Imagine you’re dictating a text message in Igbo and the system confidently transcribes “crying” when you said “cloth.” Not just a typo you can spot and fix. A completely different word that makes semantic nonsense but looks plausible.
75.5% bootstrap diacritic loss means:
3 out of 4 tone marks disappear
“cloth” → could mean “crying”
“egg” → meaning lost entirely
“bridge” → wrong word
In English, this would be like dropping 75% of consonants.
This isn’t just about transcription accuracy. It’s about whether “supporting 1,600+ languages” means anything more than “we trained on data from 1,600+ languages and didn’t check if it actually works for tonal distinctions.”
The Bigger Picture: Zeno’s Paradox of Low-Resource Languages
There’s a paper from EMNLP 2024 that talks about “The Zeno’s Paradox of Low-Resource Languages.” The basic idea: models keep claiming to support more and more languages, but the quality asymptote never actually reaches parity with high-resource languages. We get closer and closer, but never quite there.
Igbo is interesting because by speaker population (45 million people), it’s not low-resource. But by model performance, it clearly behaves like one. The gap between coverage (we trained on Igbo data) and competence (the model preserves linguistically meaningful distinctions) is huge.
omniASR claims support for 1,600+ languages. Igbo has 45 million speakers, but its tonal accuracy is 24.5% (only 1 in 4 tone marks preserved).
Coverage (in training data) ≠ Competence (preserves meaning)
This makes me think about all the other languages in that 1,600+ list. How many of them have this same gap? How many communities are using systems that confidently produce nonsense because nobody with native speaker expertise has stress-tested them?
What I Learned
Small, targeted datasets can reveal problems big datasets hide. I didn’t need thousands of hours of audio. Twenty-one carefully designed samples were enough to show systematic failure modes.
Native speaker expertise matters. Automated metrics can’t catch when “crying” is transcribed as “cloth” because the character error rate looks fine. You need someone who speaks the language to know that the semantic content is destroyed.
Bootstrap resampling is powerful for small samples. I was worried 21 samples was too few, but bootstrap confidence intervals let me quantify uncertainty rigorously. Even the pessimistic lower bounds showed substantial effects.
The monotone test is a better diagnostic than I expected. If diacritics are added to flat speech, that’s clear evidence of orthographic bias over acoustic conditioning. One simple test that revealed the core mechanism.
The Technical Details
For anyone interested in replicating this:
- I used my iPhone for recording (Voice Memos app, M4A format)
- Ran inference through Google Colab with omniASR’s official pipeline
- Computed bootstrap CIs with 10,000 iterations at the utterance level
- Created a custom DER metric to separate tonal errors from general transcription errors
- All code, data, and analysis is on GitHub and HuggingFace
The whole analysis took about half a week of evening work. Most of that was iterating on the sample design and figuring out the right statistical approach. The actual recording and inference was maybe a day.
What’s Next
This is really just a proof of concept. To make stronger claims, I’d need:
- Multi-speaker evaluation (10+ speakers across different Igbo dialects)
- Acoustic analysis (F0 contour tracking to verify what’s actually in the audio)
- Comparative evaluation (does Whisper do better? What about Google’s USM?)
- Fine-tuning experiments (can we fix this with targeted training data?)
I have ideas for all of these, but they’re bigger projects. For now, I’m focused on documenting the blind spot and making the methodology replicable.
Why I’m Sharing This
This started as curiosity about whether “multilingual” ASR systems actually work for the languages I grew up speaking. But it turned into something bigger.
There’s a tendency in ML to treat “supporting” a language as a checkbox. Train on some data, add it to the model card, ship it. But languages aren’t just data. They’re how people communicate, how they think, how they preserve culture.
When voice assistants strip tone marks from Igbo, they’re not just making transcription errors. They’re normalizing a version of the language that doesn’t preserve meaning. If every voice interface does this, what happens to how people write Igbo? Do they start thinking tone marks are optional because the AI doesn’t use them?
I don’t know the answers to these questions. But I think they’re worth asking before we claim to “support” 1,600+ languages.
Resources
If you want to explore the data or replicate the analysis:
- Dataset: HuggingFace
- Code: GitHub
- Audio samples: You can actually listen to the 21 clips and see the transcription failures yourself
The dataset is CC-BY-4.0 licensed, while the code is MIT licensed. If this is useful for your work, feel free to use it, cite it, and build on it.
Final Thoughts
This project taught me something important: you don’t need massive compute or huge datasets to find meaningful problems in ML systems. You just need to know where to look and what questions to ask.
As a native Igbo speaker, I knew what questions to ask. As someone learning ML, I knew how to design tests and interpret results. That combination turned out to be more valuable than I expected.
If you speak a language that’s “supported” by these big multilingual models, I encourage you to test them. Record some minimal pairs. Try code-switching. See if the system actually works the way you use the language, not just the way it appears in training data.
You might be surprised what you find.
Citation
If you found this work helpful, please consider citing it:
@article{obasi2026igboasr,
title = "When Your Voice Assistant Can't Hear Tones: Evaluating ASR Bias in Igbo",
author = "Obasi, Chizoba",
journal = "chizkidd.github.io",
year = "2026",
month = "Mar",
url = "https://chizkidd.github.io/2026/03/04/igbo-asr-tonal-evaluation/"
}