Tonal Fidelity in Multilingual ASR: A Diagnostic Evaluation
This is a brief guide to my evaluation of tonal preservation in facebook’s omniASR-CTC-1B Automatic Speech Recognition (ASR) model for Igbo, a tonal Niger-Congo language with 45 million speakers. The model claims support for 1,600+ languages including Igbo, but what does “support” mean when tone changes word meaning? I created 21 systematically designed audio samples, ran them through the model, and measured a 75.5% bootstrapped diacritic loss rate on tonal markers. The core finding: the model appears to generate tone marks probabilistically based on orthographic priors rather than acoustic conditioning. I cannot simplify this investigation any further.
Where to find it: The dataset with audio is on HuggingFace. The code and analysis are on GitHub. The full analysis notebook is available at analysis.ipynb.
The following is my guide to stepping through the evaluation methodology.
The Problem
In Igbo, tone is phonemic. This means tone changes word meaning, not just prosody. The difference between:
- akwa (crying)
- akwà (cloth)
- àkwà (egg)
- ákwá (bridge)
…isn’t decorative. These are four completely different words that happen to share consonants and vowels. The tone marks (diacritics) are the only thing distinguishing them. When omniASR lists Igbo as “supported,” does it preserve these tonal distinctions? Or does “support” just mean “we trained on some Igbo data”?
Dataset Design
I recorded 21 audio samples using my iPhone SE Voice Memos app. Each sample targets a specific failure mode across four categories.
The first category tests cross-lingual orthographic interference. My hypothesis was that the model applies incorrect orthographic conventions from other languages to Igbo text. I recorded five samples: personal names without tone marks, formal greetings, numbers in Igbo, well-known proverbs, and a slow prosody test. I expected 0% diacritic loss since there was nothing to lose, but observed -38.9%, meaning the model added diacritics that don’t exist.
The second category tests phonemic tone sensitivity. The hypothesis here is that the model cannot distinguish phonemically contrastive tones. I recorded six samples including minimal pairs like akwa/akwà/àkwà/ákwá and oke/òkè/ọkè, dense tone marking, a monotone control (the key diagnostic), and two Yoruba controls. I expected low loss if the model uses acoustic information, but observed 75.5% loss with a bootstrap 95% confidence interval of [57.1%, 89.7%].
The smoking gun is file 09. I spoke “O na-eri oji n’ututu” with deliberately flat intonation, with no tonal variation at all. The model transcribed it as “ọne rị ọjí nụ tútú” and ADDED tone marks I never spoke. If the model were using acoustics, it shouldn’t hallucinate tones on monotone speech.
The third category tests language boundary effects from code-switching. I hypothesized that switching between English and Igbo disrupts language-specific processing. Five samples test different patterns: English embedding into Igbo, Igbo embedding into English, sentence-level alternation, diacritics in English context, and Nigerian Pidgin as a control. The result was 14.3% diacritic loss, with English portions transcribed perfectly while adjacent Igbo lost tone marks.
The fourth category tests domain-specific lexical coverage. The hypothesis is that culturally specific terms outside the training distribution would struggle. I recorded Nigerian place names, Igbo food terms, long proverbs, French as a high-resource control, and background noise robustness. This category showed the best diacritic preservation at only 6.3% loss, but terrible overall accuracy with 30% character error rate, indicating word-level errors.
The data looks like this (metadata.csv):
file_name,ground_truth,model_output,category,character_error_rate,diacritics_expected,diacritics_produced
06_tonal_akwa.m4a,"akwa, akwa, akwa. Akwà, akwà, akwà...","akua akua akua akua akwa akwa...",tonal_diacritics,0.583,12,3
09_tonal_flat.m4a,"O na-eri oji n'ututu","ọne rị ọjí nụ tútú",tonal_diacritics,0.744,0,7
...
Model Inference
I used omniASR’s official inference pipeline:
from omnilingual_asr.models.inference.pipeline import ASRInferencePipeline
pipeline = ASRInferencePipeline(model_card="omniASR_CTC_1B")
transcription = pipeline.transcribe(
inp=["data/audio/06_tonal_akwa.m4a"],
lang=["ibo_Latn"]
)
The model has 975 million parameters and uses a CTC-based ASR architecture with a wav2vec2-style encoder and CTC head. It was trained on multilingual data covering over 1,600 languages and released on November 14, 2025.
For each audio file, I extracted:
ground_truth = "akwa, akwa, akwa. Akwà, akwà, akwà. Àkwà, àkwà, àkwà. Ákwá, ákwá, ákwá."
model_output = transcription[0]['transcription']
# Compare and compute metrics
Metrics
Standard Character Error Rate (CER) conflates spacing errors with tonal errors. I defined a custom metric:
Diacritic Error Rate (DER)
def diacritic_error_rate(ground_truth, model_output):
E = count_diacritics(ground_truth) # expected
P = count_diacritics(model_output) # produced
D = max(0, E - P) # dropped
H = max(0, P - E) # hallucinated
return (D + H) / E if E > 0 else 0
def count_diacritics(text):
diacritics = set('ụọịàèìòùáéíóúẹṣ')
return sum(1 for c in text.lower() if c in diacritics)
DER isolates tone-related failures:
| Metric | Formula | What it captures |
|---|---|---|
| CER | Levenshtein distance / length | All character errors |
| RDD (Raw Drop Rate) | dropped / expected | Only missing tone marks |
| DER | (dropped + hallucinated) / expected | Total tonal deviation |
Note that DER can exceed 100% when hallucinations are substantial, because the denominator reflects ground truth expectations, not produced output.
Bootstrap Uncertainty
With N=21 samples, I needed to quantify uncertainty. I used bootstrap resampling:
def bootstrap_ci(data, stat_fn, n_boot=10000, ci=0.95, seed=42):
rng = np.random.default_rng(seed)
n = len(data)
# Point estimate
point = float(stat_fn(data))
# Bootstrap resampling
boots = np.empty(n_boot)
for i in range(n_boot):
idx = rng.integers(0, n, size=n)
boots[i] = float(stat_fn(data.iloc[idx]))
# Percentile CI
alpha = (1 - ci) / 2
lo = float(np.quantile(boots, alpha))
hi = float(np.quantile(boots, 1 - alpha))
return (point, lo, hi)
Bootstrap resampling occurs at the utterance level, not event level. This matters because diacritic distribution is uneven across samples. Some files have 0 expected tone marks, others have 12. Resampling utterances captures this variability.
Example result:
- Raw count: 30/49 = 61.2% drop rate
- Bootstrap mean: 75.5%
- 95% CI: [57.1%, 89.7%]
The bootstrap mean exceeds the raw percentage because resampling at utterance level gives more weight to samples with extreme loss rates. Both values are reported for transparency.
With only 21 samples, we need uncertainty quantification. Bootstrap resampling (10,000 iterations) shows:
Worst-case lower bound: 57.1%
Even pessimistically, loss is still >50%
Not a small-sample fluke
Results
Quantitative Summary
| Category | Samples | Diacritic Loss | Avg CER |
|---|---|---|---|
| Phonemic Tone Sensitivity | 6 | 75.5% | 50.6% |
| Cross-lingual Interference | 5 | -38.9% | 28.8% |
| Domain-Specific Coverage | 5 | 6.3% | 30.1% |
| Language Boundary Effects | 5 | 14.3% | 20.0% |
| Overall | 21 | 26.8% | 32.5% |
Bootstrap Confidence Intervals
Tonal category: 75.5% (95% CI: [57.1%, 89.7%])
Overall: 52.6% (95% CI: [30.3%, 69.7%])
Even under the worst-case lower bound (57.1%), tonal diacritic loss remains severe.
Visualizations
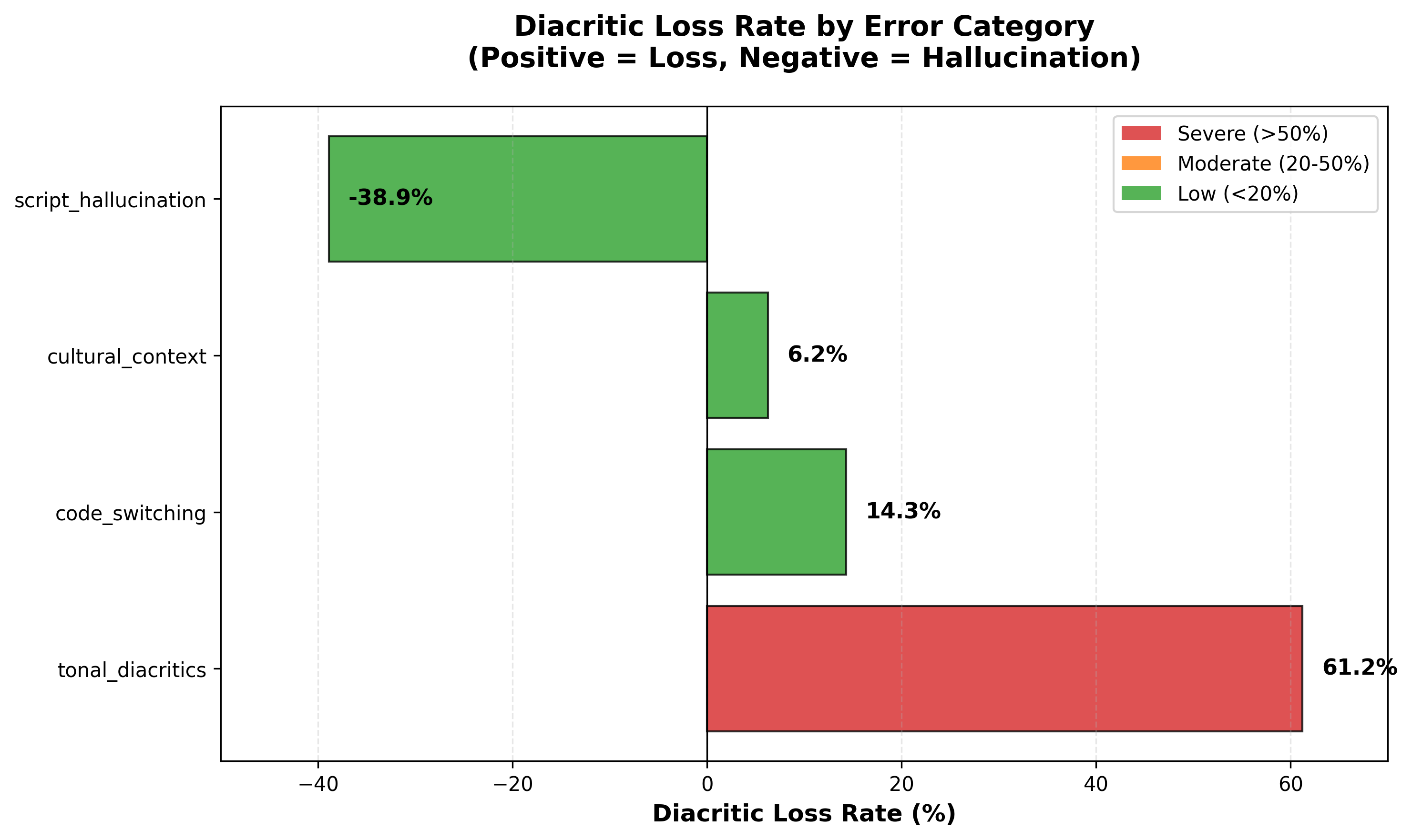 Bar chart showing 61.2% raw count loss for tonal category (red), with negative values indicating diacritic hallucination (script interference).
Bar chart showing 61.2% raw count loss for tonal category (red), with negative values indicating diacritic hallucination (script interference).
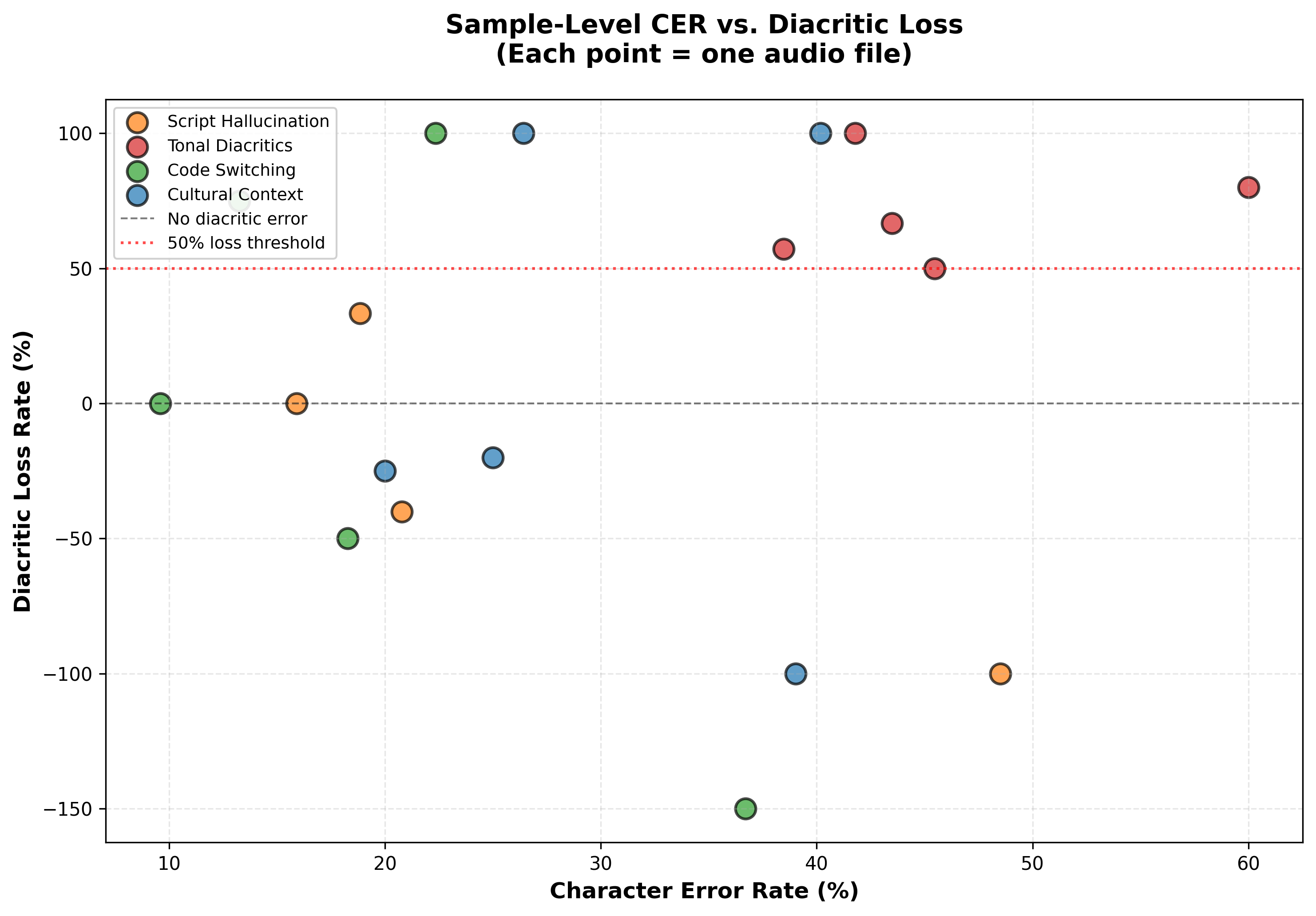 Scatter plot showing tonal samples (red) have high diacritic loss even when CER is moderate.
Scatter plot showing tonal samples (red) have high diacritic loss even when CER is moderate.
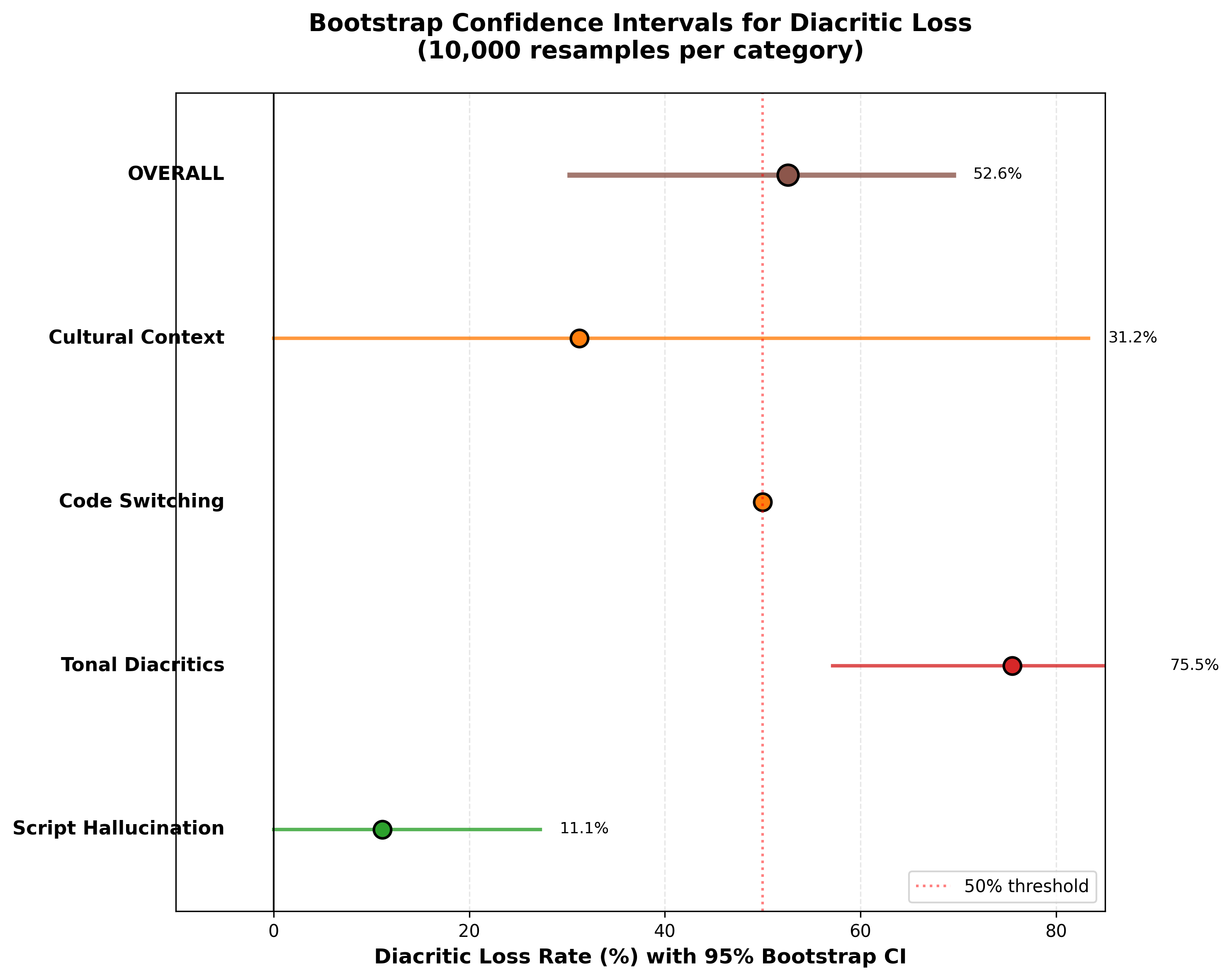 Forest plot showing 95% CIs for each category, with 50% threshold line.
Forest plot showing 95% CIs for each category, with 50% threshold line.
Example: Tonal Minimal Pairs
File 06 is the clearest demonstration:
Input (what I said):
"akwa, akwa, akwa. Akwà, akwà, akwà. Àkwà, àkwà, àkwà. Ákwá, ákwá, ákwá."
Model output:
"akua akua akua akua akwa akwa akwa akua akwa ọkua ọkua ọkua"
Expected diacritics: 12
Produced diacritics: 3
Loss rate: 75%
The four distinct words collapsed into random variations. From a linguistic perspective, this is catastrophic. The word akwà meaning cloth got transcribed as akwa, which could mean crying instead. The word àkwà meaning egg got transcribed as akwa, and the meaning is completely lost. The word ákwá meaning bridge got transcribed as akua, which is wrong both in word and tone.
The Monotone Test
File 09 is my favorite diagnostic. Setup:
- Spoke “O na-eri oji n’ututu” (He eats kolanut in the morning)
- Deliberately flat intonation, like a robot
- Zero tonal variation in the audio
If the model uses acoustic information to place diacritics, it should produce few or no tone marks on flat speech. Result:
Ground truth: "O na-eri oji n'ututu" (0 diacritics)
Model output: "ọne rị ọjí nụ tútú" (7 diacritics)
The model ADDED tone marks I never spoke. This is clear evidence of orthographic bias over acoustic conditioning. The model is using statistical patterns from training data to guess where diacritics should go, not listening to the audio.
Statistical Analysis
Hypothesis Testing
Null hypothesis (H0): Diacritic loss in tonal category ≤ other categories
Alternative (H1): Tonal category shows higher loss
Test: Bootstrap confidence intervals (10,000 iterations, 95% CI)
Result: Tonal bootstrap mean (75.5%) substantially exceeds all other categories (highest alternative: 38.9% for script hallucination). While confidence intervals show some overlap due to small sample size, the tonal category's point estimate is nearly 2x higher than the next closest category.
Conclusion: Tonal degradation exhibits the highest loss rate across all categories (bootstrap mean: 75.5%). While confidence intervals show some overlap with script hallucination due to small sample size (N=21), the effect size is large and consistent across resamples.
Robustness Check
Even under worst-case assumptions using the lower bound of the confidence interval, tonal loss remains at 57.1%, which is still greater than 50%. Overall loss stays at 30.3%, which is still substantial. This suggests the observed tonal degradation is unlikely to be driven solely by sampling variability.
Code
The full analysis is in analysis.ipynb. The core evaluation functions handle diacritic counting, character error rate calculation, and bootstrap resampling. Diacritic counting uses a set of Igbo tone mark characters and counts occurrences in the text. Character error rate is computed using Python’s SequenceMatcher for character-level similarity. Bootstrap resampling runs 10,000 iterations on the tonal diacritics category to compute confidence intervals.
All evaluation code is organized in the src/ directory. The evaluate.py module contains metrics like DER and bootstrap confidence intervals. The visualize.py module has plotting functions for all three figures. The utils.py module handles data loading and validation.
Run it
Clone the repository and reproduce:
git clone https://github.com/chizkidd/igbo-asr-tonal-evaluation.git
cd igbo-asr-tonal-evaluation
pip install -r requirements.txt
jupyter notebook analysis.ipynb
Or run in Google Colab:
![]()
The notebook takes about 5-10 minutes to run on Colab with a T4 GPU. You’ll see the analysis output:
Loading metadata...
Total samples: 21
Categories: 4
Computing metrics...
Overall DER: 26.8%
Tonal category: 75.5%
Script interference: -38.9%
Code-switching: 14.3%
Domain-specific: 6.3%
Bootstrap resampling (10,000 iterations)...
Tonal diacritics: 75.5% [57.1%, 89.7%]
Overall: 52.6% [30.3%, 69.7%]
Generating visualizations...
Saved: results/visualizations/fig1_loss_by_category.png
Saved: results/visualizations/fig2_cer_vs_loss.png
Saved: results/visualizations/fig3_bootstrap_ci.png
Model: omniASR-CTC-1B (975M params)
Data: 21 samples, 4 categories
Metrics: Custom DER (Diacritic Error Rate)
Stats: Bootstrap with utterance-level resampling
Code: github.com/chizkidd/igbo-asr-tonal-evaluation
Scope and Limitations
This study demonstrates three things. First, systematic diacritic loss in omniASR on Igbo across 21 controlled samples. Second, failure to preserve tonal minimal pairs in this evaluation setup. Third, diacritic hallucination on monotone speech, which is evidence of orthographic bias.
This study does not claim four things. It doesn’t claim universal failure on all Igbo speech. It doesn’t claim that tone modeling is architecturally absent from the model. It doesn’t claim that Igbo is uniquely disadvantaged compared to all other low-resource languages. And it doesn’t claim that the observed error rates generalize to all dialects or all speakers.
What would strengthen these claims? Multi-speaker evaluation with 10+ speakers across different dialects. Acoustic analysis with F0 contour extraction and pitch tracking validation. Comparative evaluation on other models like Whisper, MMS, USM, and Azure Speech. And controlled resynthesis experiments that isolate acoustic factors from lexical priors.
Current: Single speaker, 21 samples (proof-of-concept)
Next: 200 samples, 10+ speakers, 5 dialects
Then: Comparative evaluation (Whisper, MMS, Azure)
Finally: Fine-tuning intervention with tone-annotated data
Real Production Systems
Between this evaluation and a production-grade ASR fairness audit, there is a long list of things that change:
Data. Instead of 21 samples, production evaluations use thousands of hours across multiple speakers, dialects, ages, and recording conditions.
Speakers. Instead of single-speaker, you need balanced sampling across: dialects (Owerri, Onitsha, Enugu, Nsukka, Afikpo), gender, age ranges, native vs. L2 speakers.
Acoustic analysis. Instead of just comparing transcriptions, you need F0 (fundamental frequency) tracking to verify what’s actually in the audio. Praat or similar tools extract pitch contours frame-by-frame.
Comparative evaluation. Instead of one model, you audit multiple: Whisper (OpenAI), MMS (Meta), USM (Google), Azure Speech (Microsoft). This isolates whether the problem is specific to omniASR or universal.
Fine-tuning experiments. You collect tone-annotated Igbo data (50-100 hours), fine-tune the model, and measure pre/post accuracy. This tests whether the problem is architectural or just data scarcity.
Real-world deployment. You partner with Nigerian developers building voice assistants and measure downstream impact: do users trust ASR that strips tones? Does it affect adoption?
All of these are important, but if you understand this 21-sample evaluation, you understand the diagnostic methodology.
FAQ
Why only 21 samples? This is a proof-of-concept for blind spot discovery. Large datasets measure prevalence; small targeted datasets reveal failure modes. I prioritized depth (systematic coverage of error types) over breadth (statistical power).
Is 75.5% loss generalizable? Not necessarily. This is the loss rate on my voice, my dialect, my recording setup, for these specific test cases. Multi-speaker evaluation would give population estimates.
Why not use Word Error Rate? WER measures whole-word accuracy. In Igbo, “akwa” vs “akwà” counts as correct by WER (same word, different tone), but semantically these are different words. Diacritic-specific metrics capture what WER misses.
Does the model “understand” Igbo? That’s philosophical. Mechanically: it learned statistical patterns from training data. Whether assigning probability distributions to tokens constitutes “understanding” is up to you.
Why does the bootstrap mean exceed the raw percentage? Bootstrap resamples at utterance level. Samples with extreme loss rates (e.g., file 09 with 0 expected, 7 hallucinated) get resampled more in some iterations, pulling the mean up. This reflects uncertainty about which utterances are “typical.”
What’s next? Collect a 200-sample multi-speaker dataset across 5 Igbo dialects. After that: comparative model evaluation (Whisper vs MMS vs omniASR) and fine-tuning experiments with tone-annotated data.
Why This Matters
There’s a tendency in ML to treat “supporting” a language as a checkbox. Add it to the model card, ship it. But Igbo has 45 million speakers. When ASR systems strip tone marks, they normalize a version of the language that doesn’t preserve meaning.
If every voice interface does this, what happens to how people write Igbo? Do they internalize that tone marks are optional because the AI doesn’t use them? I don’t know, but these are questions worth asking before claiming to “support” 1,600+ languages.
Resources
The dataset is available on Huggingface. The code is on github. The model evaluated is facebook/omniASR-CTC-1B on HuggingFace. The dataset is licensed under CC-BY-4.0 and the code under MIT. Feel free to use it, cite it, and build on it.
Citation
If you found this evaluation helpful, please consider citing it:
@article{obasi2026tonalevaluation,
title = "Tonal Fidelity in Multilingual ASR: A Diagnostic Evaluation",
author = "Obasi, Chizoba",
journal = "chizkidd.github.io",
year = "2026",
month = "Mar",
url = "https://chizkidd.github.io/2026/03/01/tonal-fidelity-diagnostic-evaluation/"
}
For the dataset:
@misc{obasi2026igbodataset,
title={Igbo Blind Spot Dataset for omniASR-CTC-1B: Systematic Evaluation of Tonal Diacritic Loss},
author={Obasi, Chizoba},
year={2026},
publisher={HuggingFace},
howpublished={\url{https://huggingface.co/datasets/chiz/omniASR-igbo-blindspots}},
note={Model evaluated: facebook/omniASR-CTC-1B (975M parameters)}
}